

I got free GPU credits from Runpod. Receive free credits at this link.
Quick intro
LeetArxiv is Leetcode for implementing Arxiv and other research papers.
This is part of our series on Practical Index Calculus for Computer Programmers.
Part 1: Discrete Logarithms and the Index Calculus Solution.
Part 2: Solving Pell Equations with Index Calculus and Algebraic Numbers.
Part 3: Solving Index Calculus Equations over Integers and Finite Fields.
Part 4 : Pollard Kangaroo when Index Calculus Fails.
Part 5 : Smart Attack on Anomalous Curves.
Part 6: Hacking Dormant Bitcoin Wallets in C.
1.0 Introduction
I had 20 dollars in free GPU credits from Runpod so I spent the weekend learning CUDA by building a big integer library.
Big integers are numbers with lots of bits. They are used in cryptography to protect passwords. Libraries like LibGMP, FLINT and OpenSSL work great on CPU. On GPU however, that’s another story.
Here’s the Colab notebook and here’s the GitHub with the C and CUDA code.
This article is split into these sections:
CPU Benchmark code.
We code CPU addition, multiplication and modular inverse for 256 bit numbers.
Compare our code’s running time and accuracy to libGMP.
GPU Benchmark code.
We log into Colab and quickly convert C code to CUDA.
2.0 CPU Benchmark Code
We need a CPU-based metric. Ours shall be a custom-made C library that handles 256 bit integers versus LibGMP in C.
*Lol I used the tricks I saw in LibGMP’s source code. idk if it counts haha
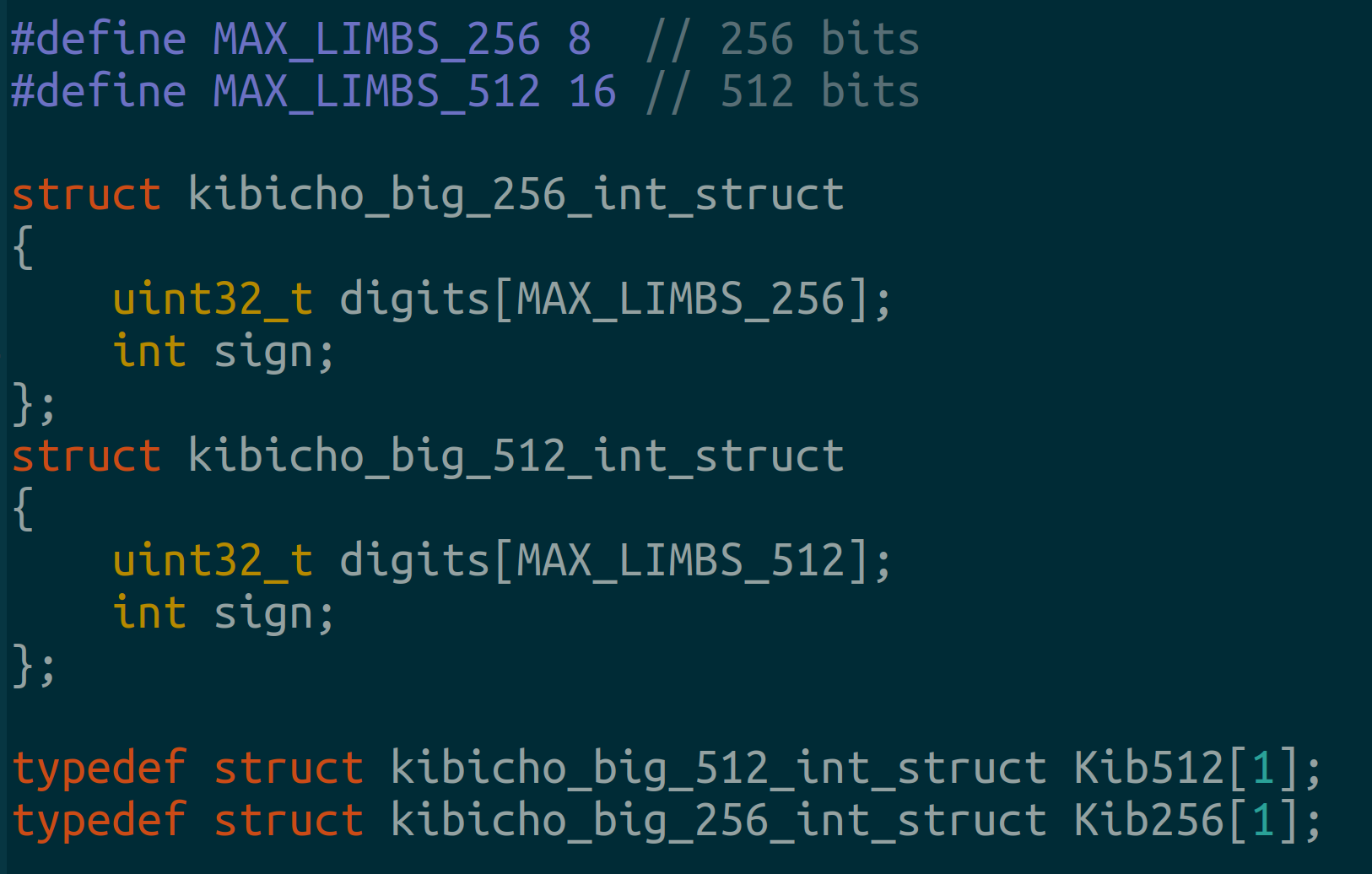
2.1 Big Integer Data Structures
A common pattern observed in OpenSSL and LibGMP is the use of unmalloc’d, one dimensional arrays to typedef structs. This helps us:
Avoid unsafe memory gotchas.
Keep everything on the stack and avoid slow heap allocations.
Code readability goes up.
*I loathe seeing symbols in my code so much that I avoid Rust and C++ because of the syntax.
We store our integers in limbs. Our example uses unsigned 32 bit integer arrays. These are 8 limbs for 256 bit arithmetic and 16 limbs for 512 bit arithmetic.
*The most significant bit is in the leftmost limb(the array at index MAX_LIMB-1)
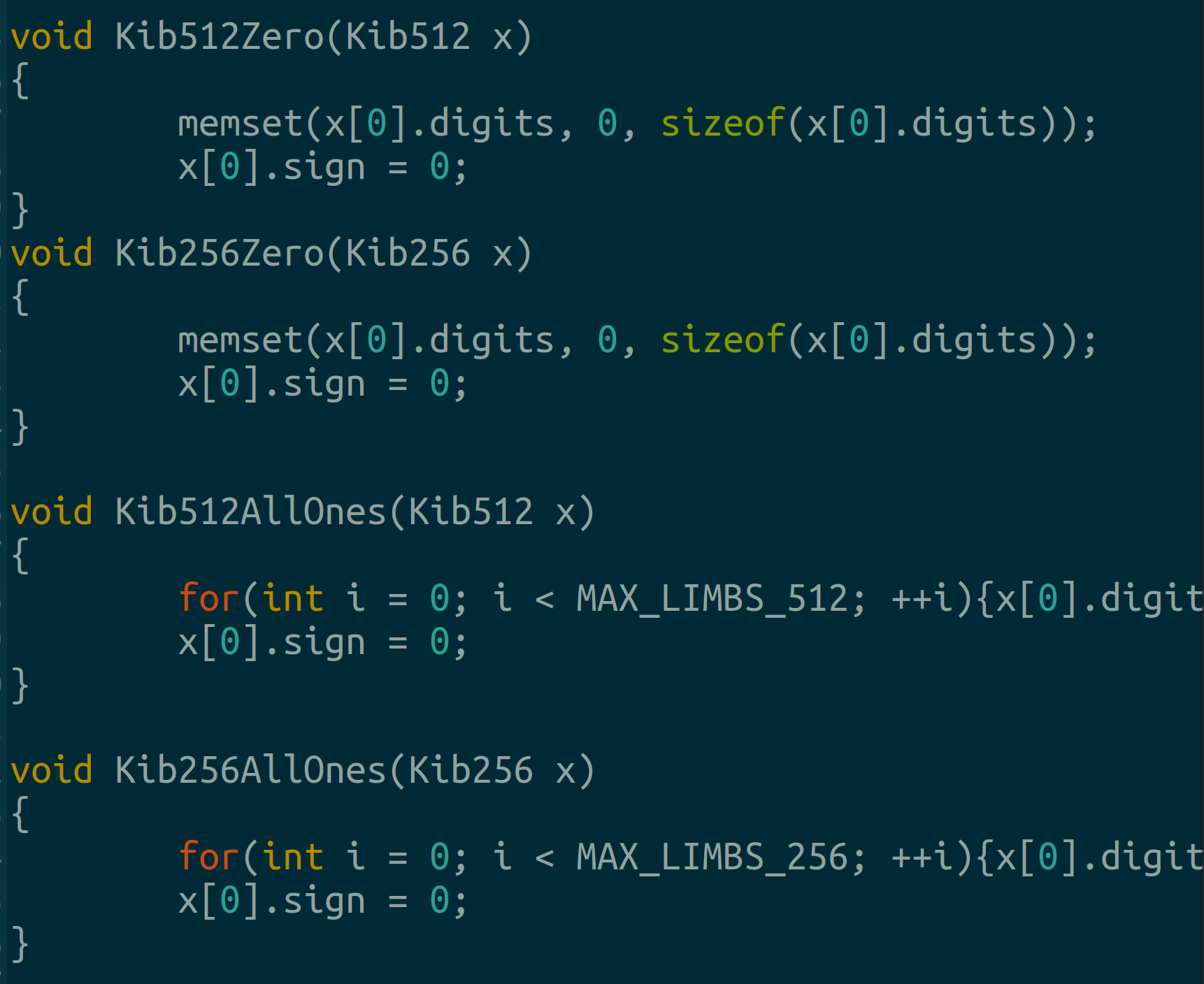
BTW using 1 dimensional arrays further makes ops like zeroing and setting all bits to 1 pretty fast
2.2 Signed Addition and Subtraction
We implement signed addition by perfoming magnitude tests. We start from the most significant limb and add towards the least significant limb. We use 64 bit unsigned integers to handle carries.
There are two addition cases to handle:
Signs are similar.
Signs are different, like negative plus positive.
2.2.1 Addition/Subtraction with Similar Signs
When the signs are similar, we ignore the sign and just add like you would on pencil and paper.
*Computers use 2’s complement so addition and subtraction are the same thing if magnitudes are same.
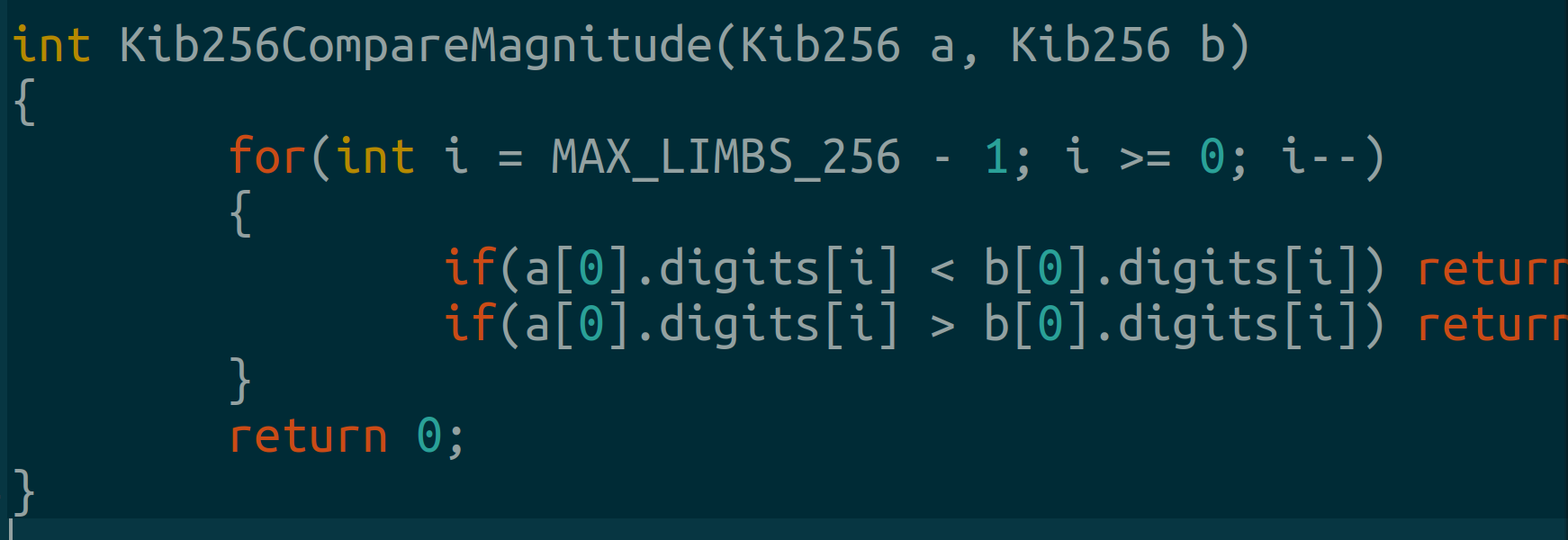
First we write an absolute value comparison function. It ignores the sign and compares from the largest bit to the smallest bit limb.
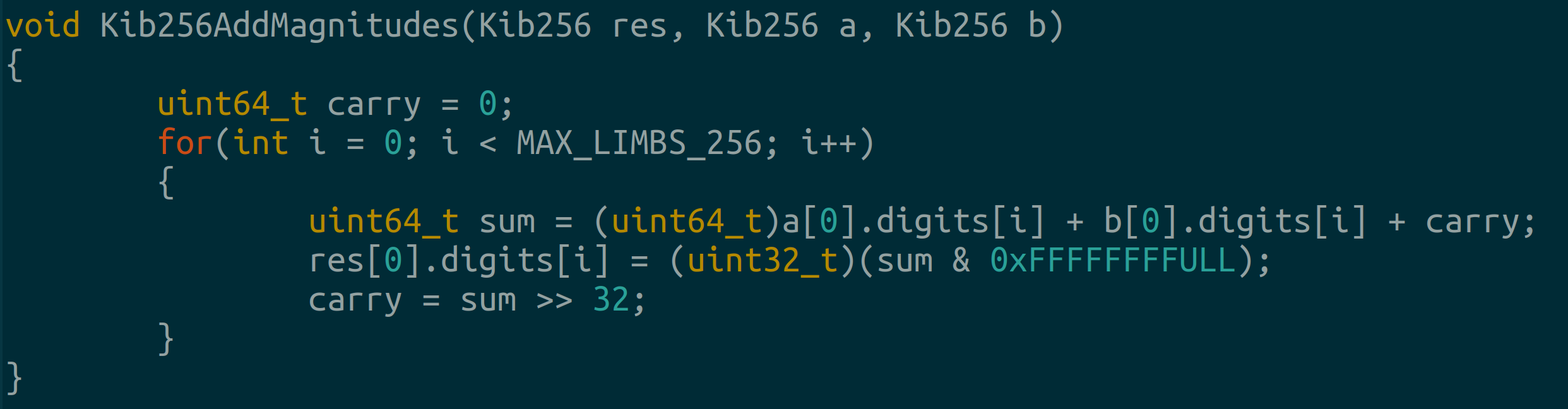
Then we write a pretty simple addition function that carries in an unsigned 64 bit data type.
2.2.2 Addition with Different Signs
Different signs mean we’re working with positive and negative integers. In this case, we subtract the absolute value of the larger integer from the smaller.
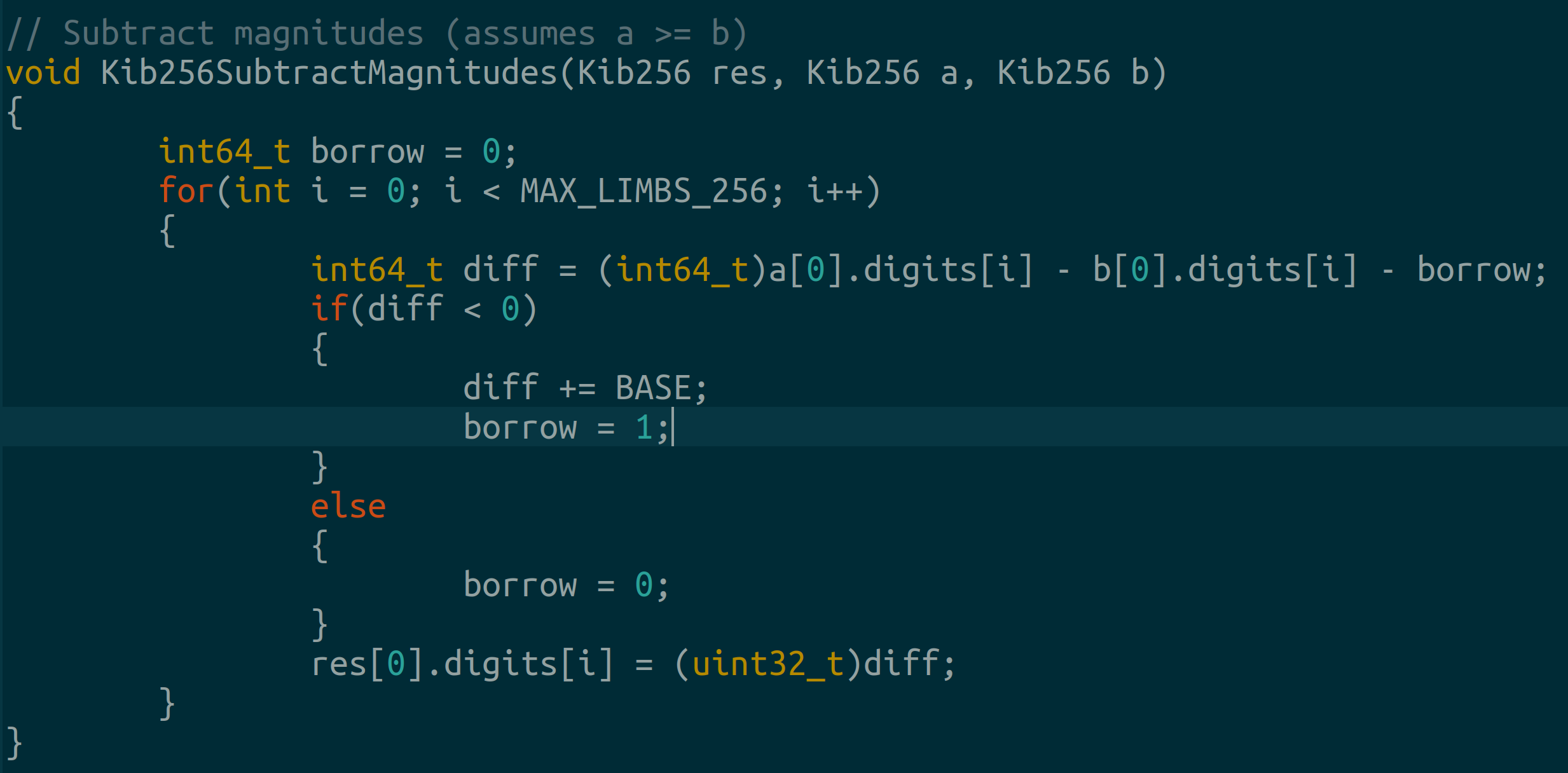
2.2.3 Final Addition/Sub Function
We use a single addition function to wrap around our different edge cases.
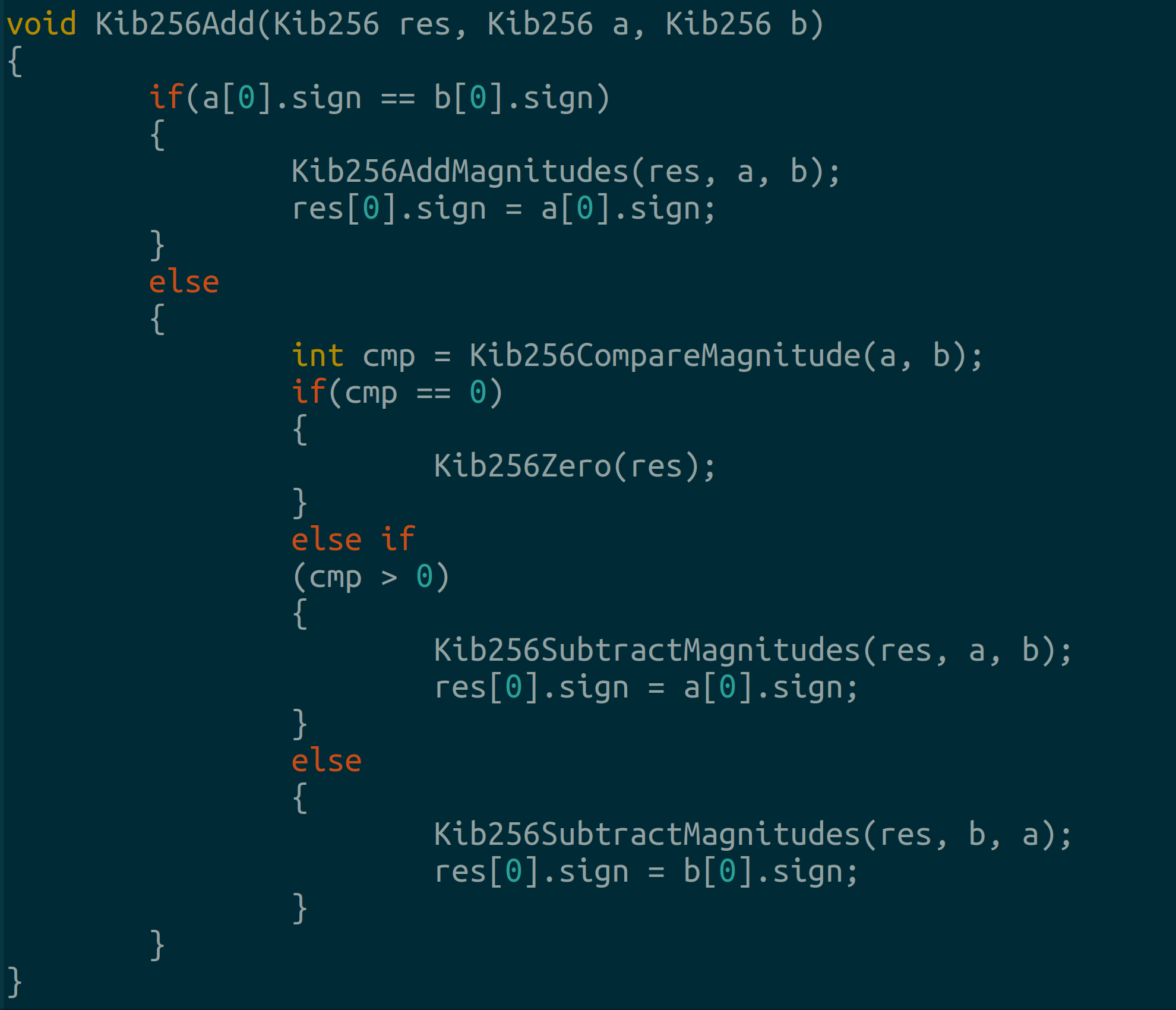
2.3 Signed Multiplication and Modulo
Our library is designed for finite fields. Division isn’t well defined in finite fields so we need not implement it. We just need a good multiplier and a good (enough) modulo function.
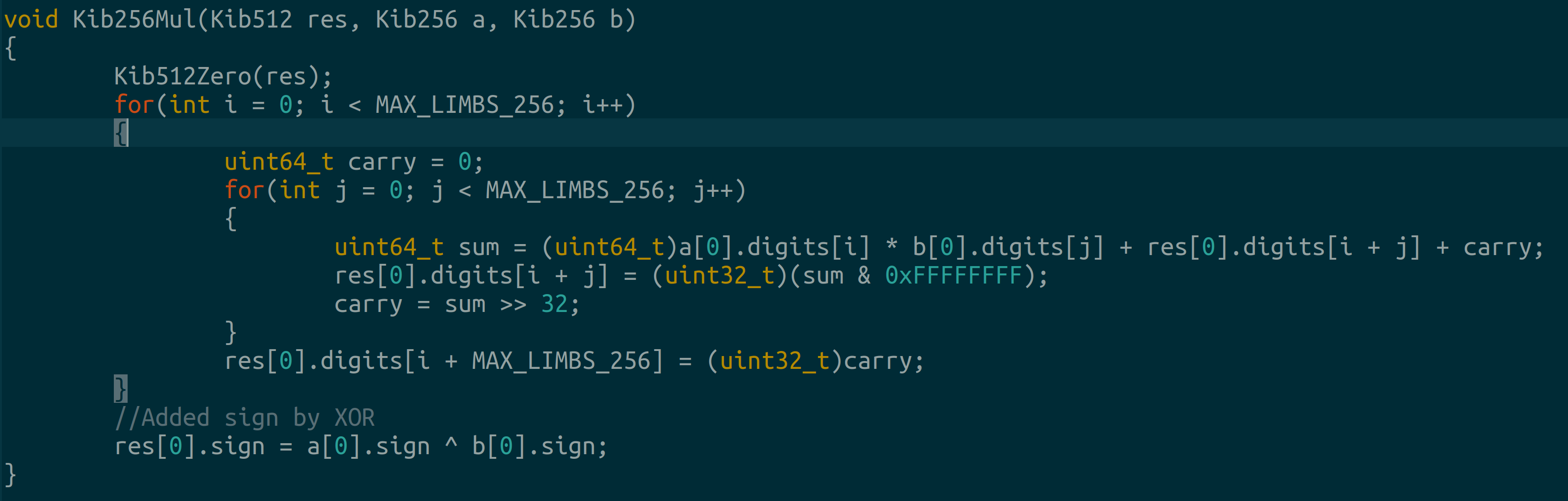
We implement usual grade school multiplication. Nothing fancy. Observe that we store our multiplication result in a 512 bit data type.
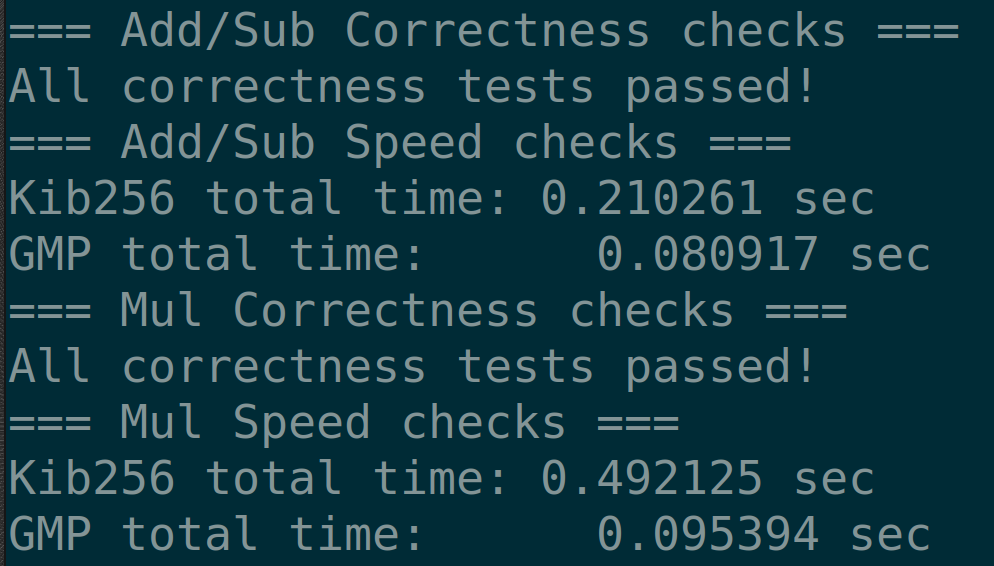
2.5 CPU Benchmark
LibGMP absolutely mogs our code. However, our implementation is correct and that’s all that matters lol*.
*yes, the copium is strong with this one
3.0 CUDA Code
Here’s the thing: converting from C to CUDA is pretty simple. I did it in this Colab notebook.



Struct definitions and function logic remains the same.
We affix __device__ keyword to functions we want to run on GPU.
Replace memset with an array because CUDA doesn’t support memset.
Next we write a multiplication kernel:
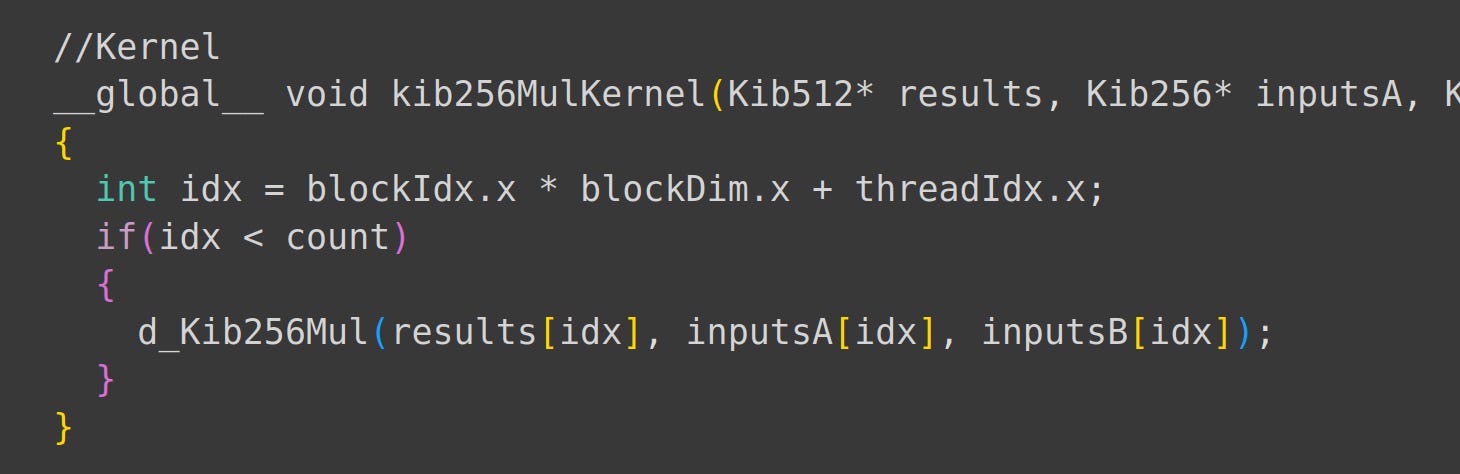
Finally, we add code to handle GPU threads and allocate GPU memory for our structs. Tbh, I didn’t expect it to be this easy.
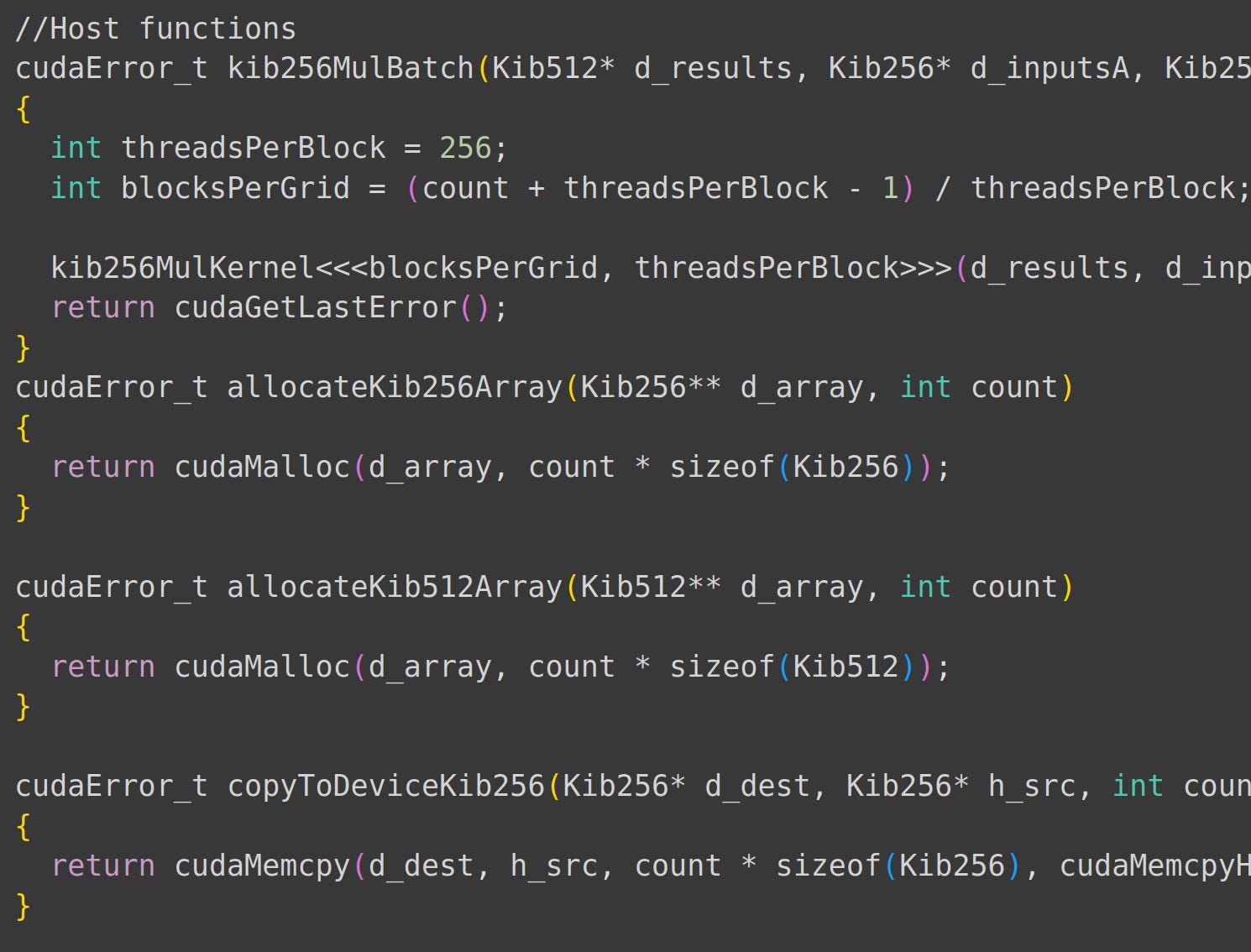
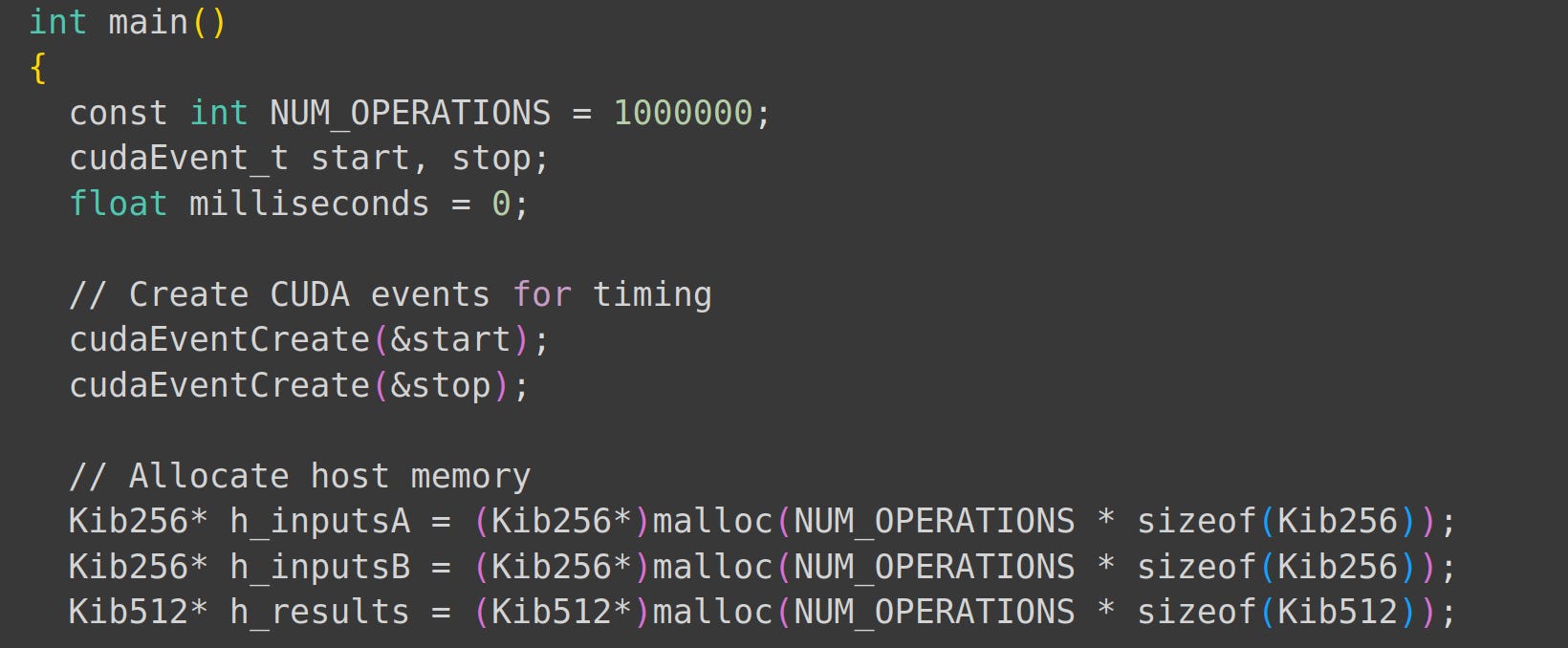
Our main function is split into these parts:
Allocating memory for the GPU.
Majority of the main function does this lol.
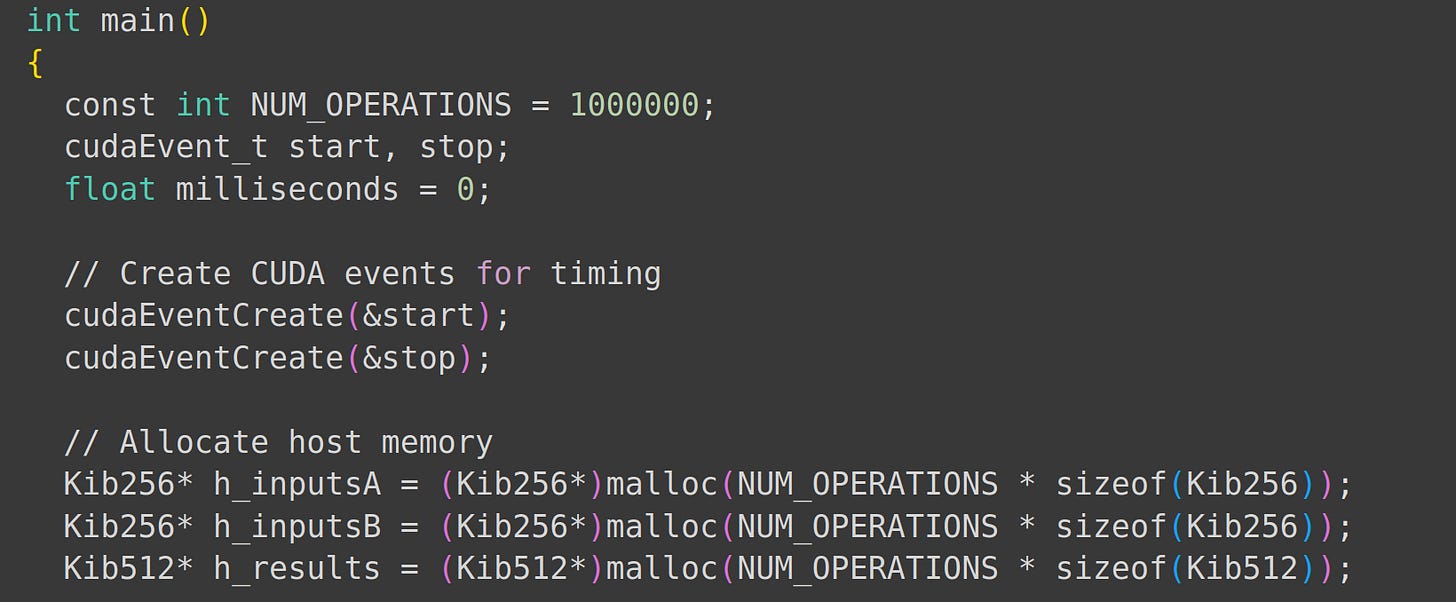
Allocating host memory
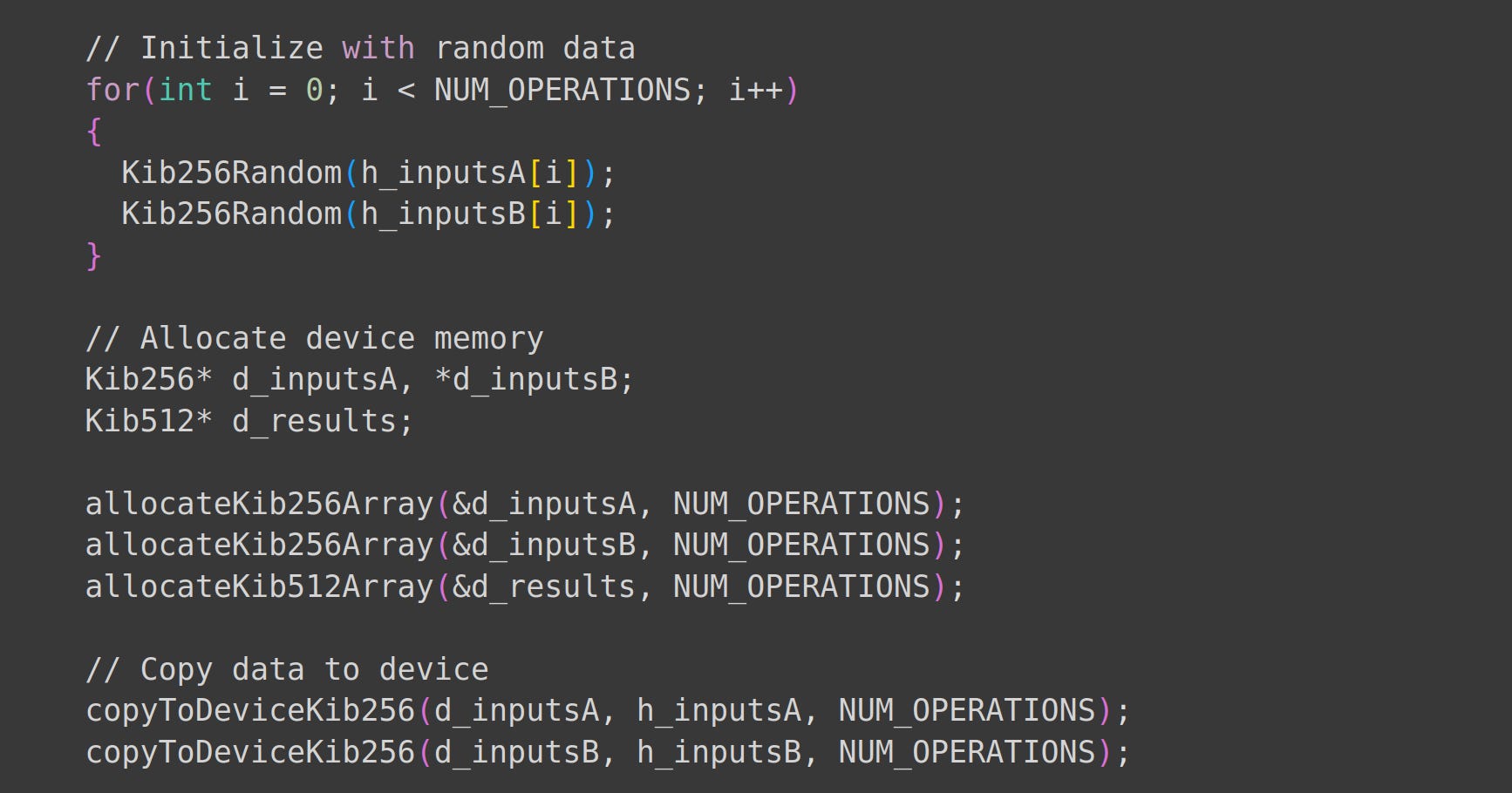
Next, we initialize our inputs and allocate device memory and array memory.
Again, I’m baffled how intuitive this was.
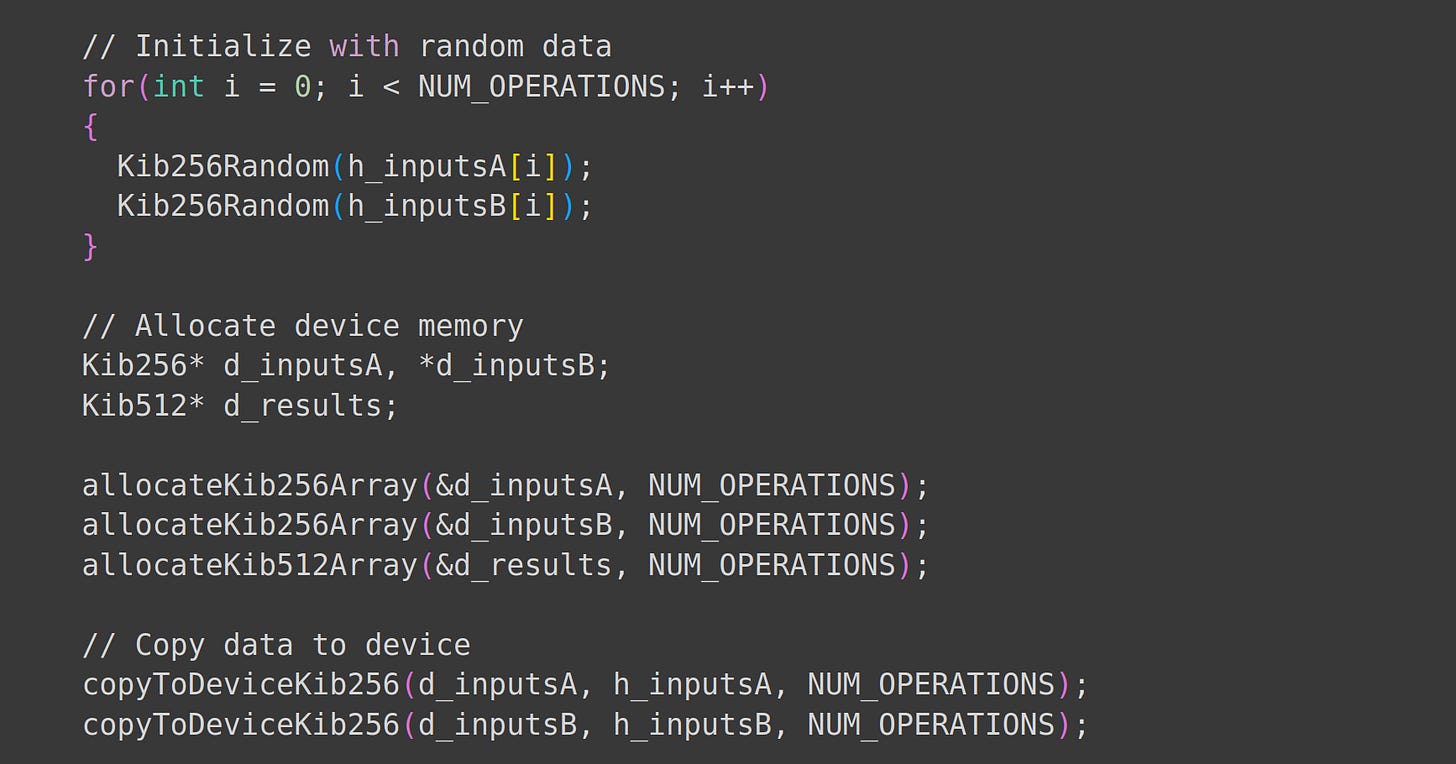
Allocating memory for arrays and device
Finally, we run our batched matmuls and free allocated memory.
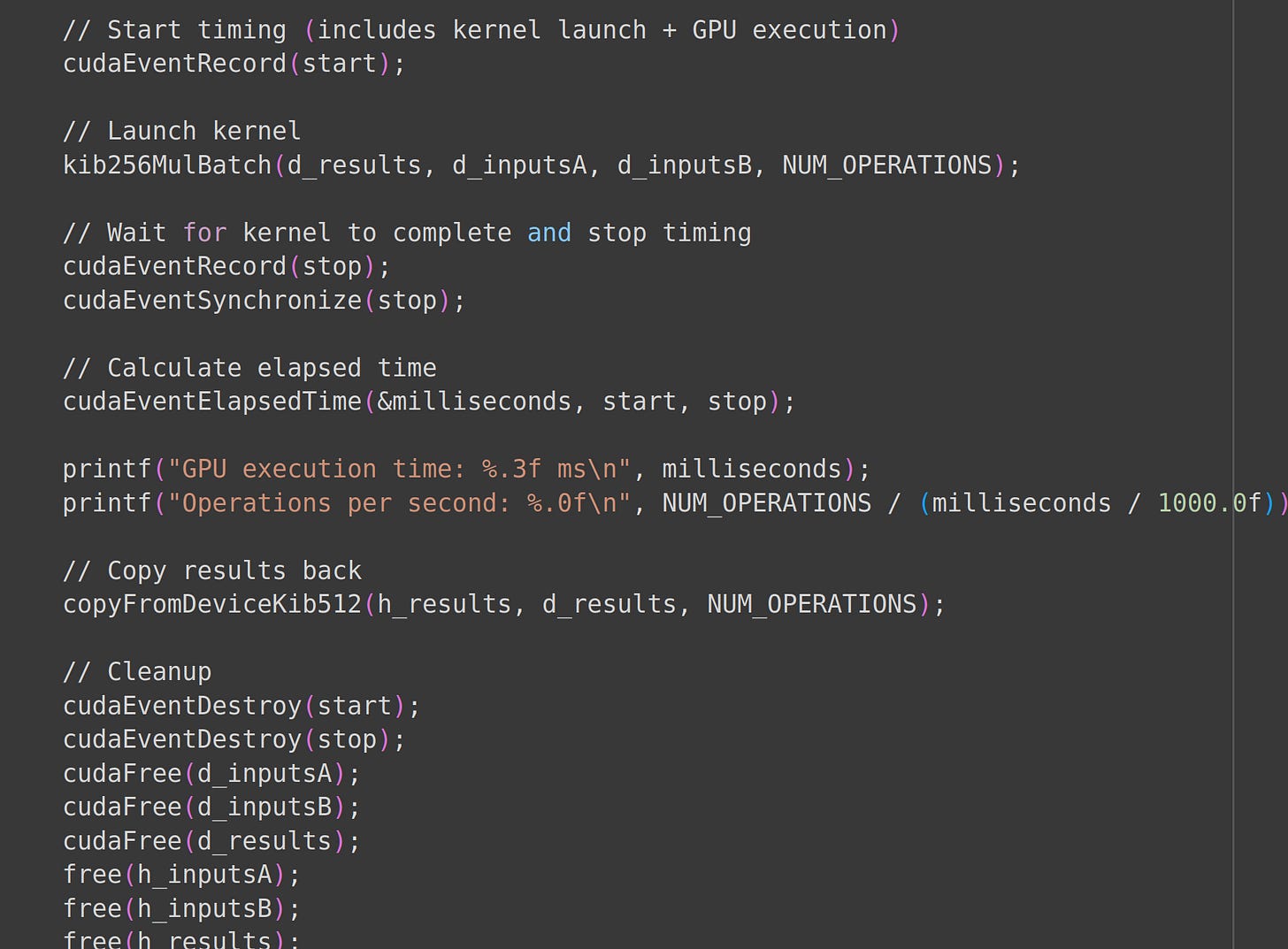
Running multiplication kernel and freeing memory
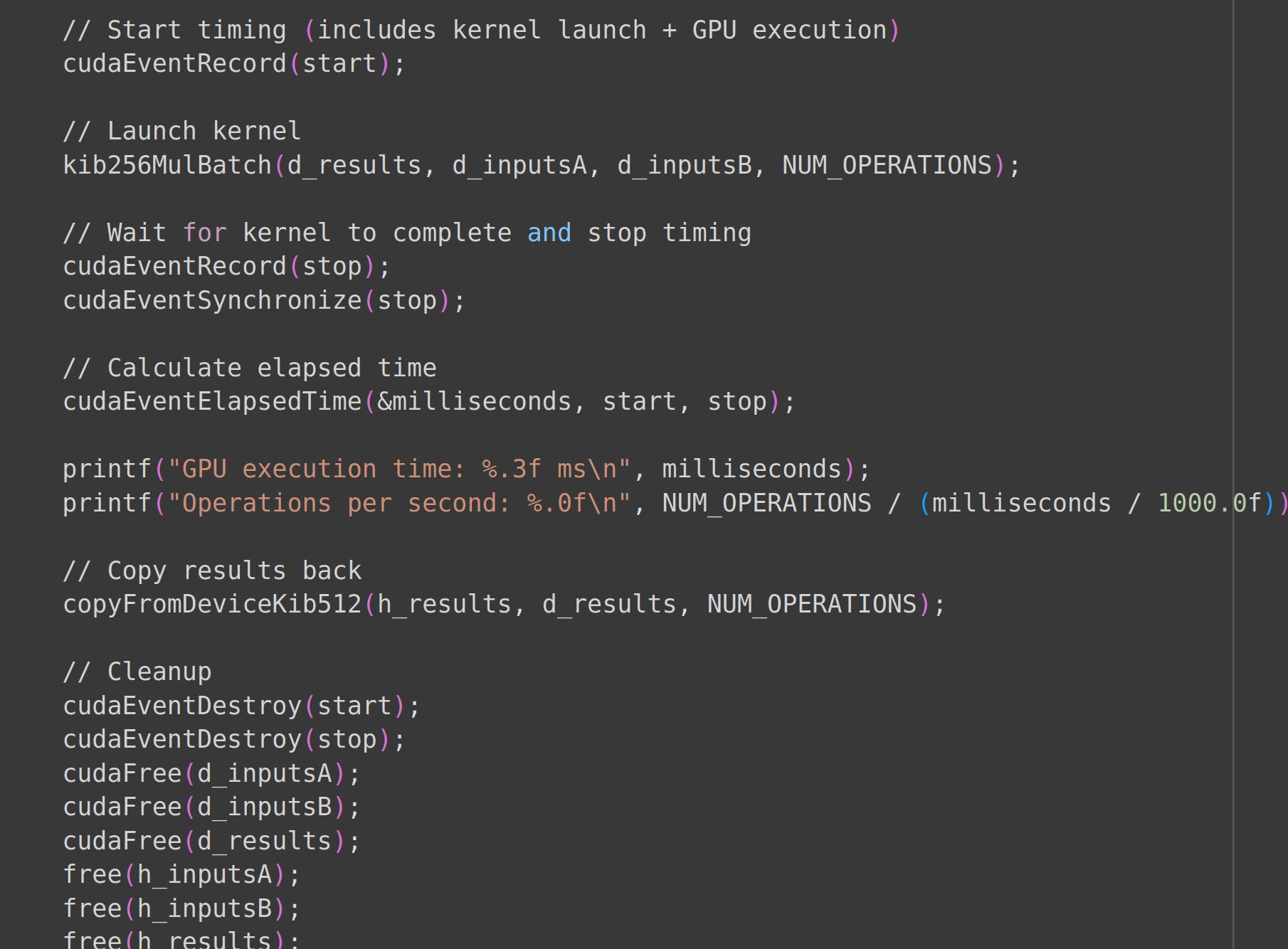
What are the results?
Our 256 bit integer GPU code took 12 milliseconds to perform as many multiplications as our CPU code.

Our CPU library took 512 milliseconds while the GPU took 12 milliseconds. Amazing!
I got free GPU credits from Runpod. Receive free credits at this link :)


