
Quick Intro
LeetArxiv is a successor to Papers With Code after the latter shutdown.
Here is 12 months of Perplexity Pro on us.
Here’s 20 dollars to send money abroad.
Here are some free gpu credits :)
Here’s some free Polymarket credits.

Quick Summary
This paper formalizes the use of large primes during the ‘relation collection’ phase of index calculus.
Code is available on Google Colab and GitHub.
1.0 Paper Introduction
We’ve coded index calculus over integer rings, finite fields, Pell curves and even Elliptic curves.
One problem plagues us: collecting relations is the most cumbersome part of the index calculus technique.
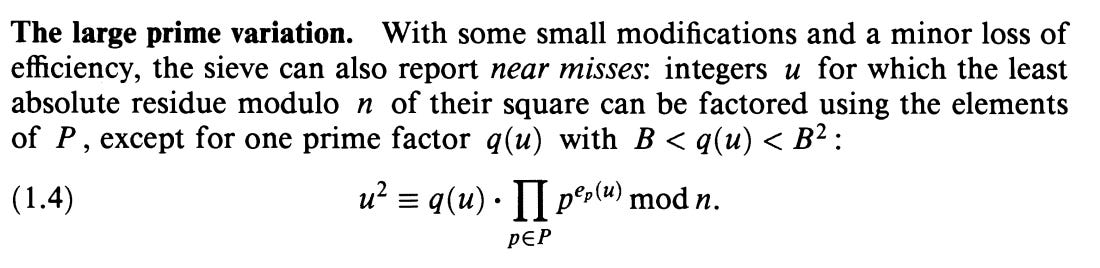
The paper Factoring with Two Large Primes (Lenstra & Manasse, 1994)1 demonstrates how to increase efficiency by utilising ‘near misses’ during relation collection.
The authors make these assertions:
It is always better to use a single large prime variation than it is not to use large primes at all.
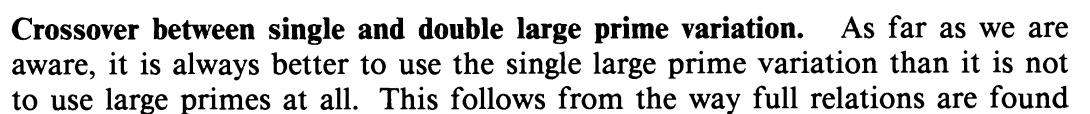
They assert the need for large primes. Taken from page 11 of (Lenstra & Manasse, 1994) Using large primes leads 50% to 60% time savings when collecting relations.

They find 50-60% time saved during relation collection. Taken from page 3 of (Lenstra & Manasse, 1994)
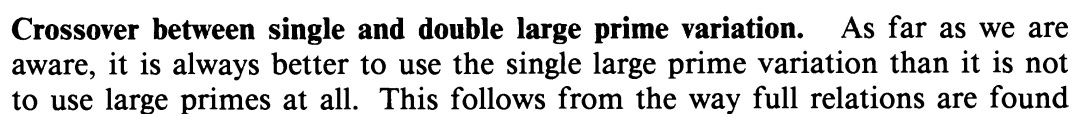

2.0 The Algorithm
We assume familiarity with the index calculus technique. A friendly introduction is available below:
2.1 How Large Primes Occur
We use the medium prime trick from (LaMacchia & Odlyzko, 1991)2 to find fractional relations during relation collection.

So we collect relations of the form:
XF_YF → Full relation factors completely over factor base.
XF_YP → 1 large prime (in Y) outside factor base.
XP_YF → 1 large prime (in X)
XP_YP → 2 large primes (one in X, one in Y)
This paper demonstrates how to combine large primes to turn partial relations into full relations.
2.2 Graph Theory Terms

The authors utilise graph theory techniques to combine relations.
Some relevant definitions are:
Vertices - each large prime number is a unique vertex.
Edges - every relation connecting prime numbers is an edge.
Connected components - a subset of vertices that are connected.
Fundamental cycle - an independent cycle formed when you add an edge between two already connected vertices.
The authors provide the formula below to cound the number of fundamental cycles:
#fundamentalCycles = e - v + cIn our case, e is a count of unique relations (edges), v is the number of unique large primes (vertices) and c counts how many partial relations can combine to form full relations. (connected components).
2.3 Putting Everything Together
The authors provide these steps to combine
Use a hash table to count all unique relations (finding e).
Use another hash table to find all unique primes (finding v).
Use the union-find algorithm to see if any large primes occur more than once.
3.0 Coding
This section is in Python and CUDA.
3.1 Preprocessing Step
The authors use a hash table with linear probing to identify unique relations.
*I guess hash tables were revolutionary in 1994. They dedicate 2 pages to linear probing lol.
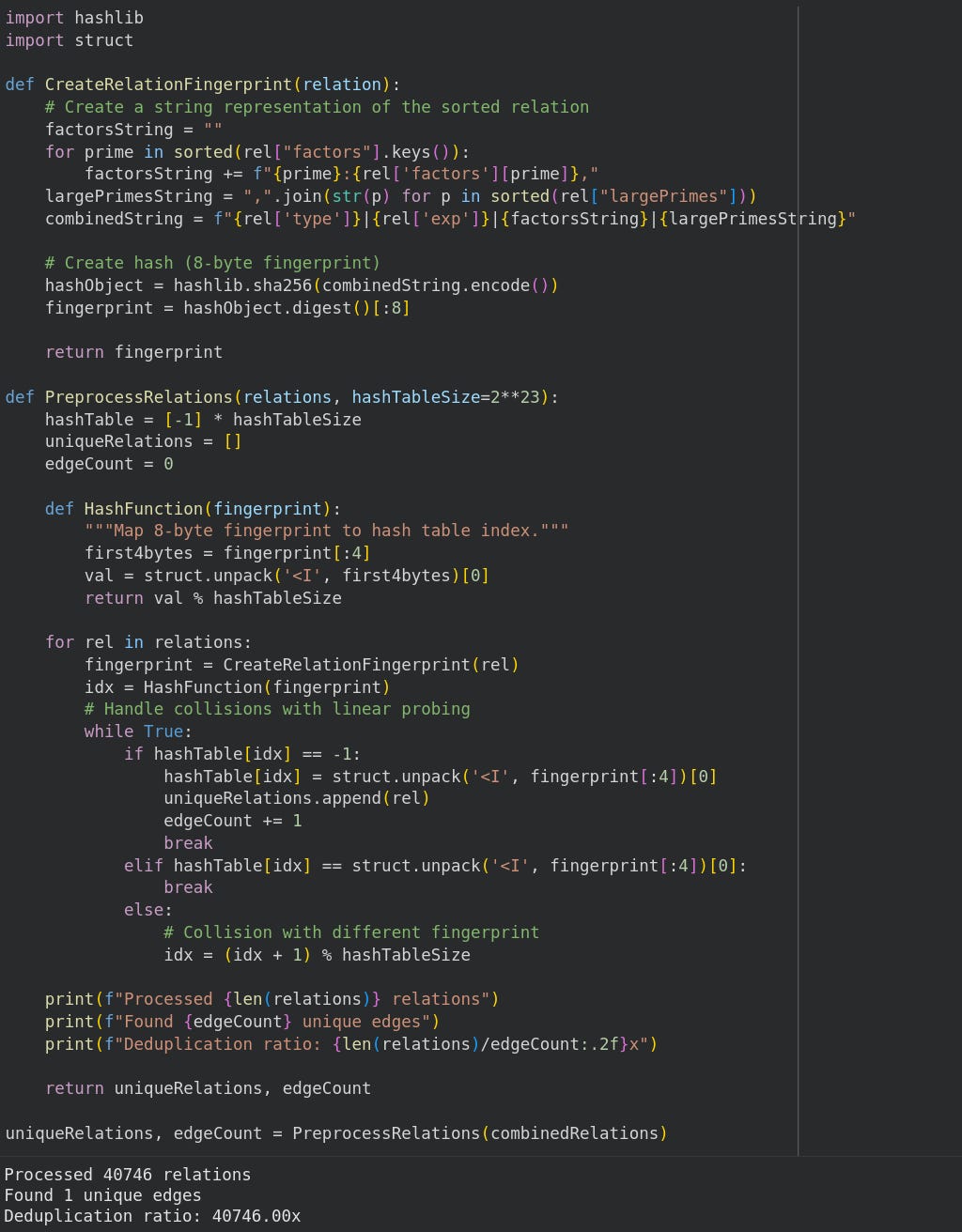
This section could easily be a single line of Python. You can follow the Colab notebook.
For the curious however, the authors do this:
Create a string representation of the sorted relation.
Hash the string representation.
Insert the hashed string in a list and handle collisions with linear probing
3.2 Union Find to Count Cycles
They suggest using the union-find algorithm to count cycles in the large prime graph:
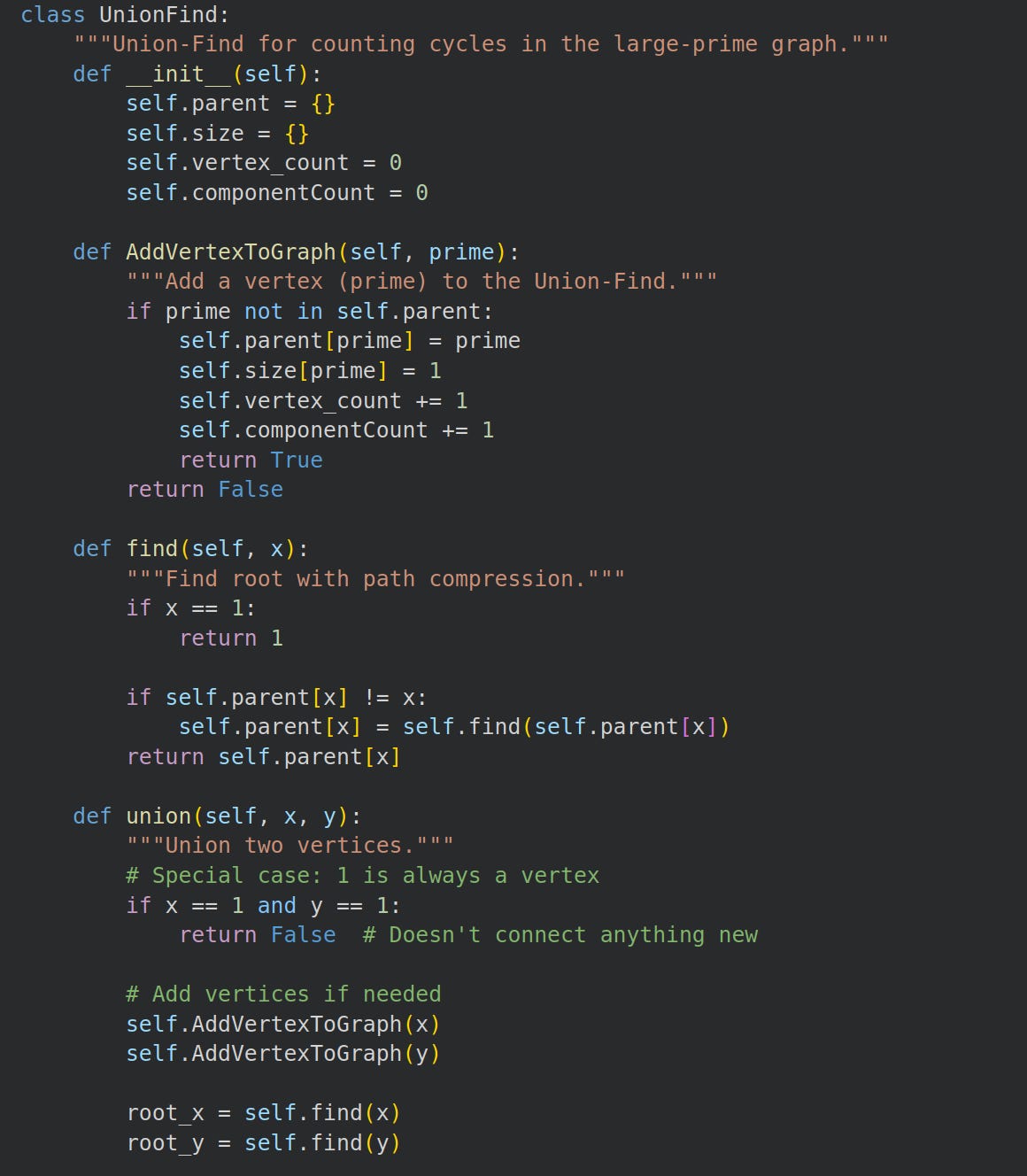
Their approach seems awfully complicated.
The goal is to find 2 relations with a mutual large prime so in 20 lines of Python:
4.0 CUDA Code
There’s little opportunity for parallel CUDA processing tbh. The hash table deduplication step might benefit from GPU parallelization.
So let’s write a hash table in CUDA.
As usual, we set up our CUDA environment on Colab:

Next, we write a simple insert for each thread:
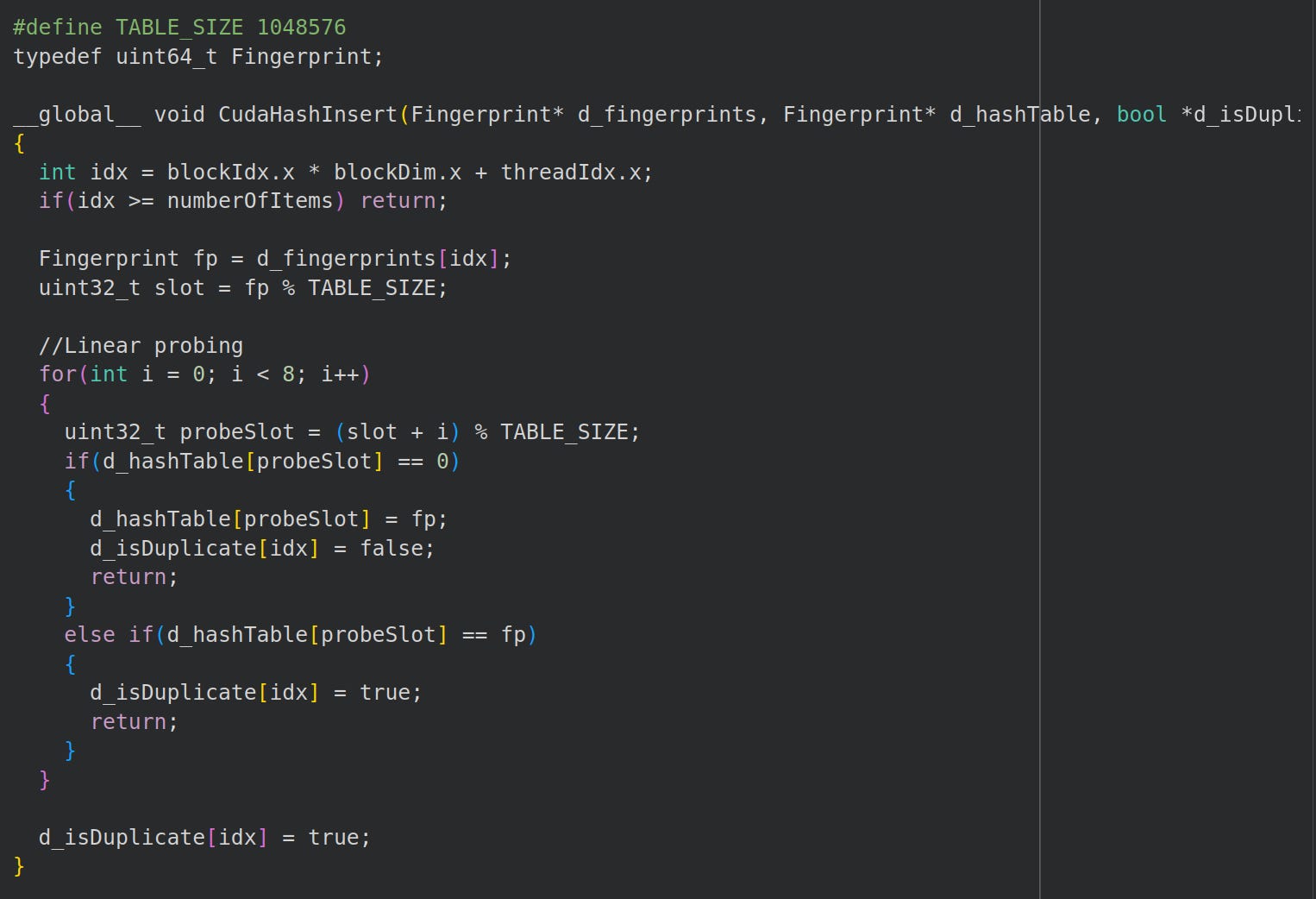
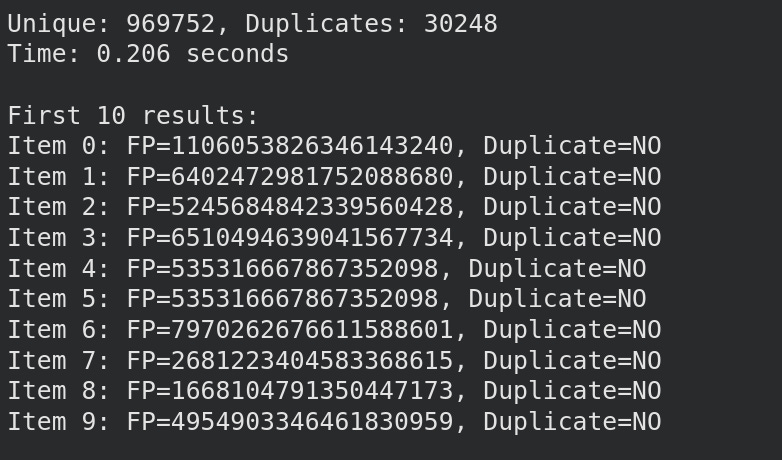
Finally, we write our parallelized hash table:

We’re done. We can dedupe in parallel lol!
5.0 Further Reading
This is part of our series on Practical Index Calculus for Computer Programmers.
Part 1: Discrete Logarithms and the Index Calculus Solution.
Part 2: Solving Pell Equations with Index Calculus and Algebraic Numbers.
Part 3: Solving Index Calculus Equations over Integers and Finite Fields.
Part 4.1 : Pollard Kangaroo when Index Calculus Fails.
Part 4.2 : Pohlig-Hellman Attack.
Part 5 : Smart Attack on Anomalous Curves.
Part 6: Hacking Dormant Bitcoin Wallets in C.
Here are some free gpu credits if you made it this far lol.
References
Lenstra, A & Manasse, M. (1994). Factoring with Two Large Primes. Mathematics of Computation, Vol. 63, No. 208 (Oct., 1994), pp. 785-798. American Mathematical Society.
