

Quick Intro
LeetArxiv is a successor to Papers With Code after the latter shutdown.
Here is 12 months of Perplexity Pro on us.
Here’s 20 dollars to send money abroad.
Here are some free gpu credits :)
Here’s some free Polymarket credits.

Code can be found at this Github repo :) and this Google Colab.
1.0 Paper Introduction

The 2018 paper Online Normalizer Calculation for Softmax (Milakov & Gimelshein, 2018)1 addresses two shortcomings with the original softmax:
The naive softmax suffers from underflow and overflow when inputs are extreme (Tianlong, 2025)2.
The safer version of the naive softmax cannot run in parallel on GPU (Wangkuiyi, 2025)3.
2.0 The Shortcomings of the Original Softmax
Page 2 of the paper is dedicated to understanding Softmax’s shortcomings.
2.1 Original Softmax Overflow/Underflow
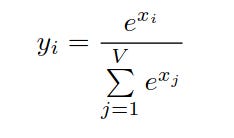
The original softmax scans the input vector two times (Milakov & Gimelshein, 2018):
First time to calculate the normalization vector.
Second time to compute the output values y.
The drawback is overflow/underflow due to the exponent.
2.1 Safe Softmax Multiple Memory Access
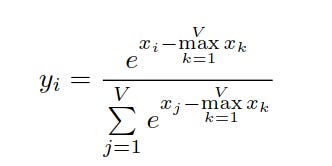
The safe softmax addresses the exponent overflow/underflow by scanning the input vector to find a maximum input.
However, it requires three passes over the input vector (Milakov & Gimelshein, 2018). This translates to 4 memory access per vector element overall.
3.0 Online Softmax Calculation

The authors use a pretty clever trick to calculate the online normalizer in one loop (Tianlong, 2025).
Instead of first finding the maximum, the authors propose rescaling the accumulated sum whenever a new max is encountered.

As summarized in (Tianlong, 2025)
At each step S, where mS is the maximum until step S, the sum of the normalizer terms can be written as:
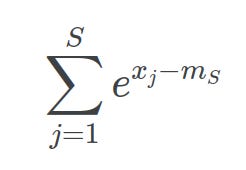
Then we can split the expression into step S-1 and step S:

Splitting the sum into a recurrence of timesteps. Image taken from (Tianlong, 2025) Finally, substituting mS-1 into our equation proves that online softmax is equivalent to the safe softmax:

Making the final substitution. Image taken from (Tianlong, 2025)
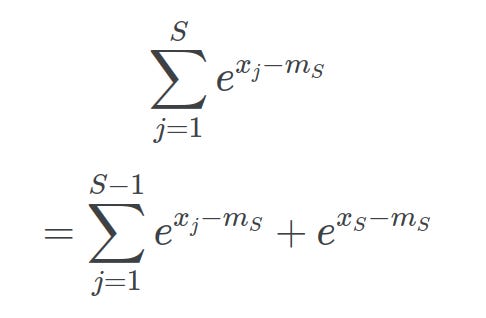
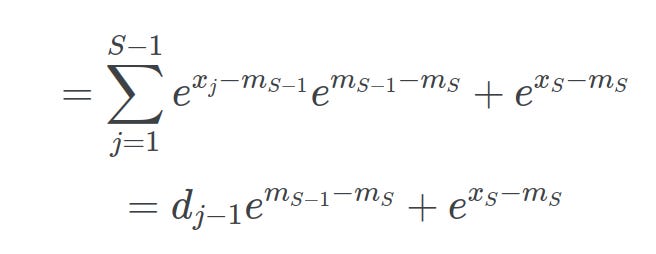
4.0 Coding Online Softmax in C
First we’ll write the three softmax versions for CPU then compare performance.
Jump to #Section 4.4 for the CPU benchmarks.
Here’s the punchline: Safe Softmax is better for CPU than Online softmax in practice due to branching.
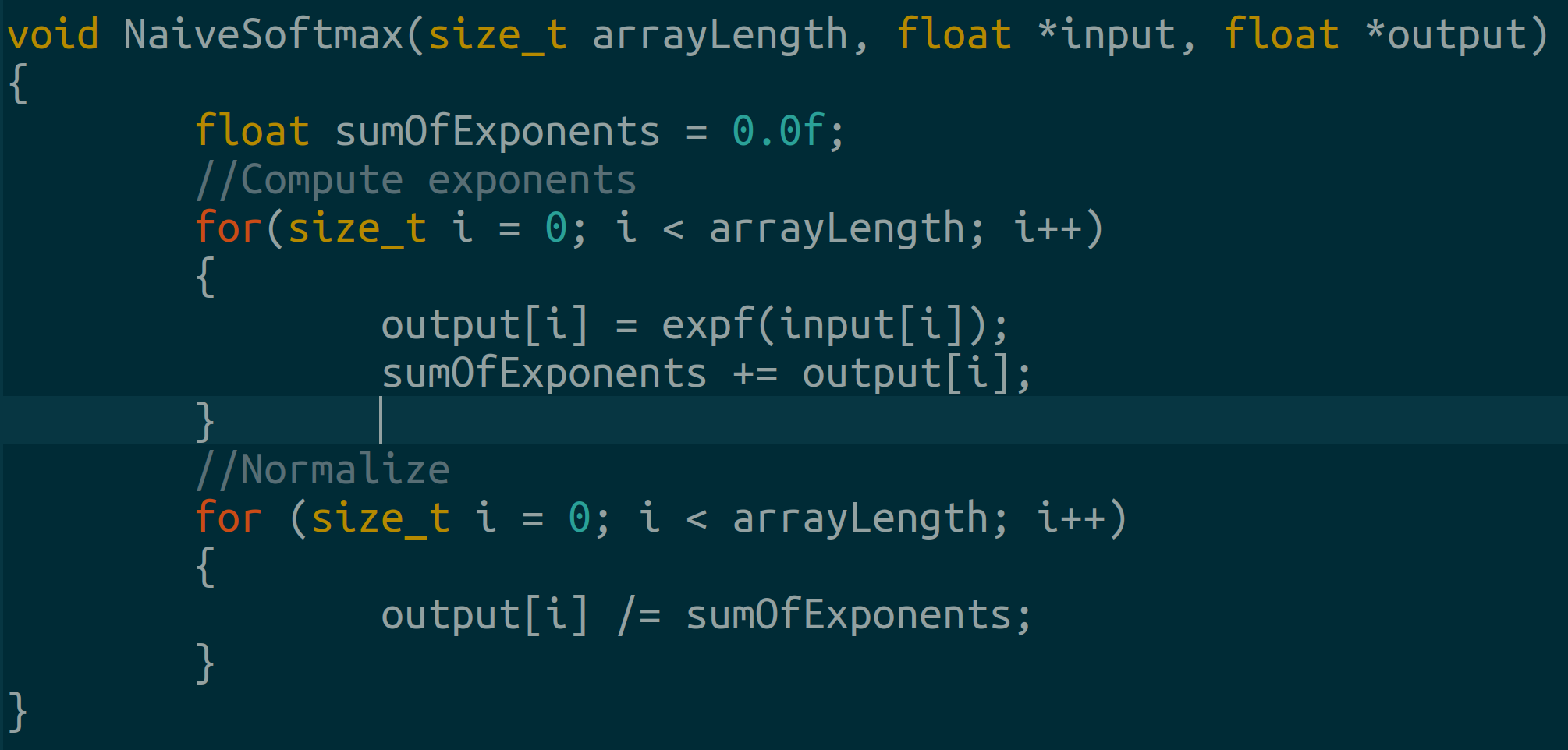
4.1 Naive Softmax
We write the original softmax that suffers from overflow/underflow as:
The first pass sums the exponents.
The second pass normalizes the output.
*Observe we have two for loops
4.2 Safe Softmax
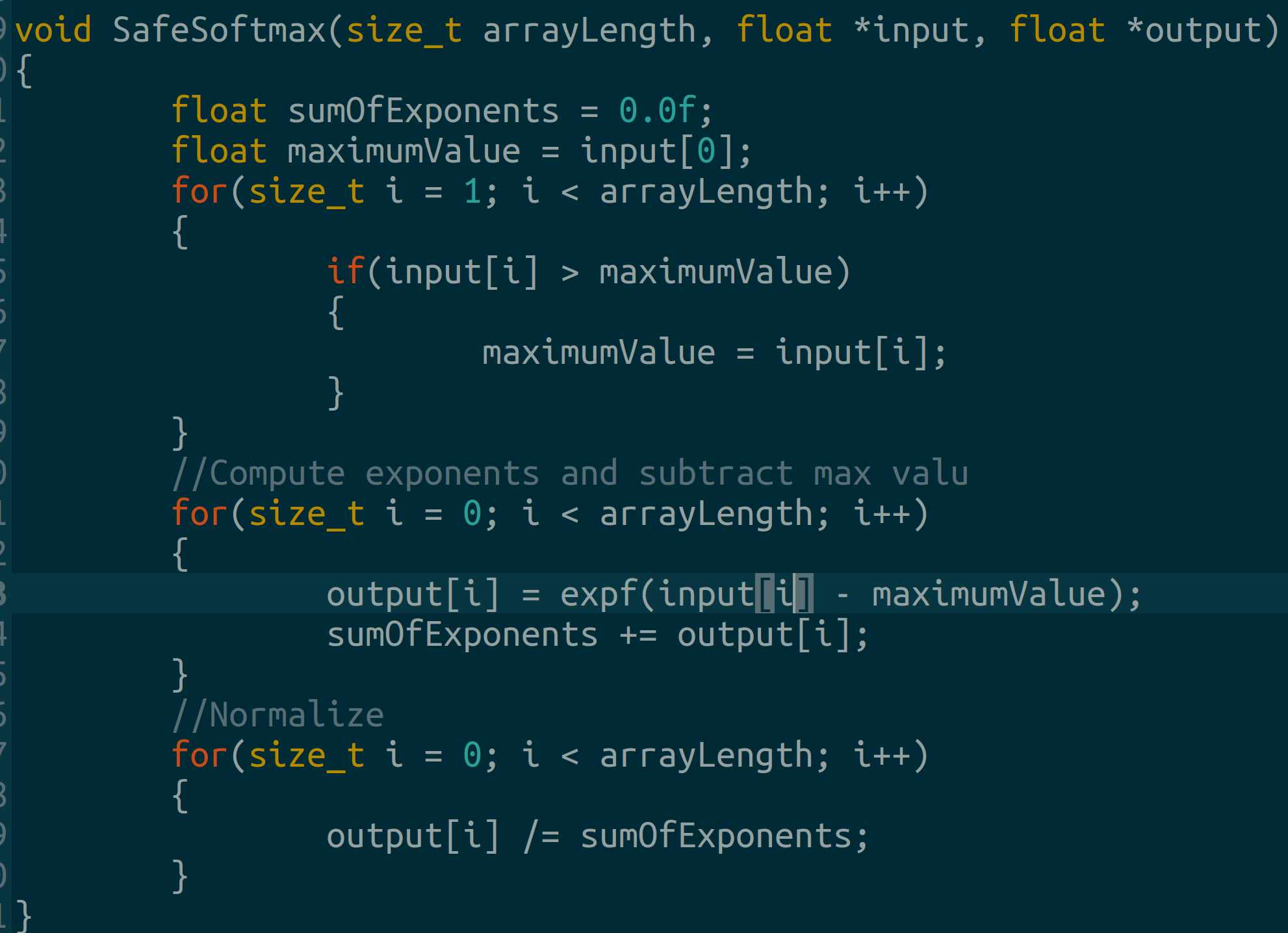
Next, we write the safe softmax in three passes:
First pass: find the array maximum.
Second pass: Compute exponents and subtract the maximum.
Third pass: Normalize the output
* We need three different for loops
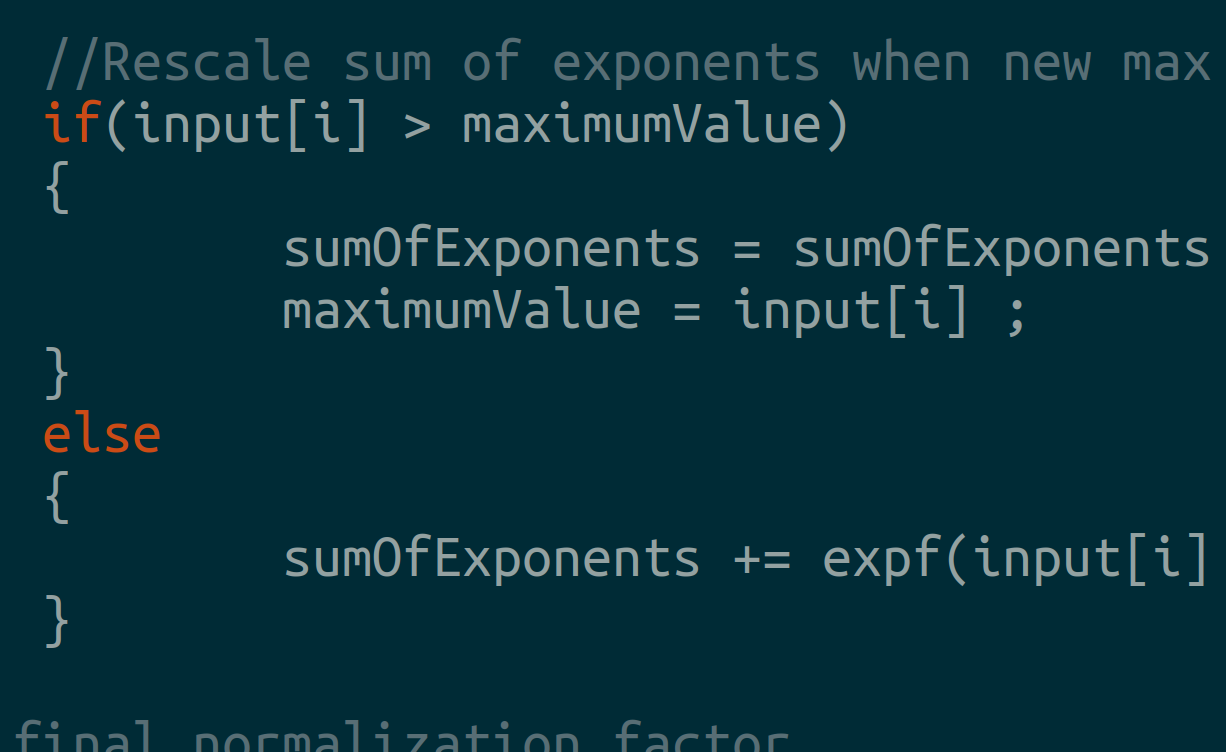
4.3 Online Softmax
This requires only two for loops:
First pass: Update maximumValue and sum exponents.
Second pass: Normalize output.

4.4 Benchmark

On CPU, safe softmax is 0.002s faster than online softmax.
This is caused by the branching if statement in our online softmax for loop.
This will happen on GPU, but the gains from parallelization are greater.
Here are some free gpu credits if you made it this far lol.
5.0 Coding Online Softmax in CUDA
This section demonstrates a C-style CUDA approach to optimizing softmax.
Follow along on Google Colab’s free GPUs here.
Our goal is to have each block of GPU threads process a single softmax array, and the threads within each block process small chunks of the array (Maharshi, 2025)4.
First we write a basic CPU softmax for later comparison.
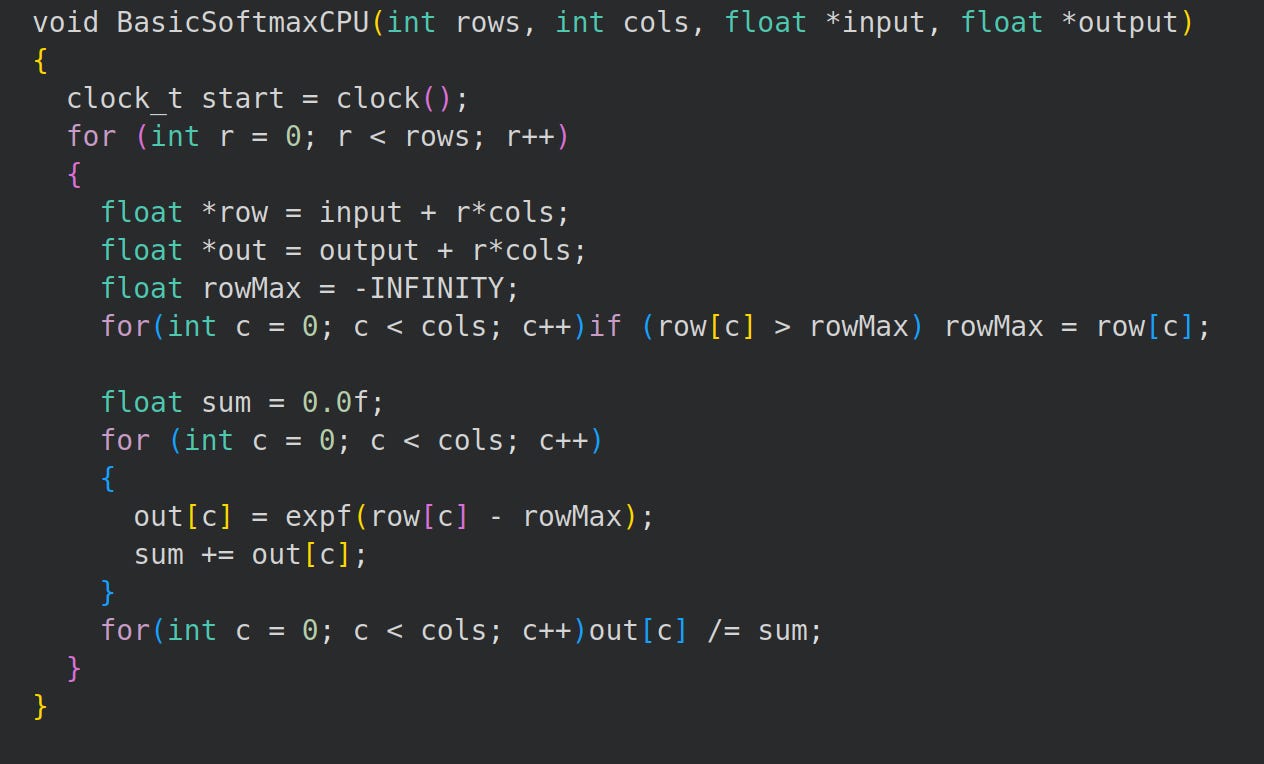
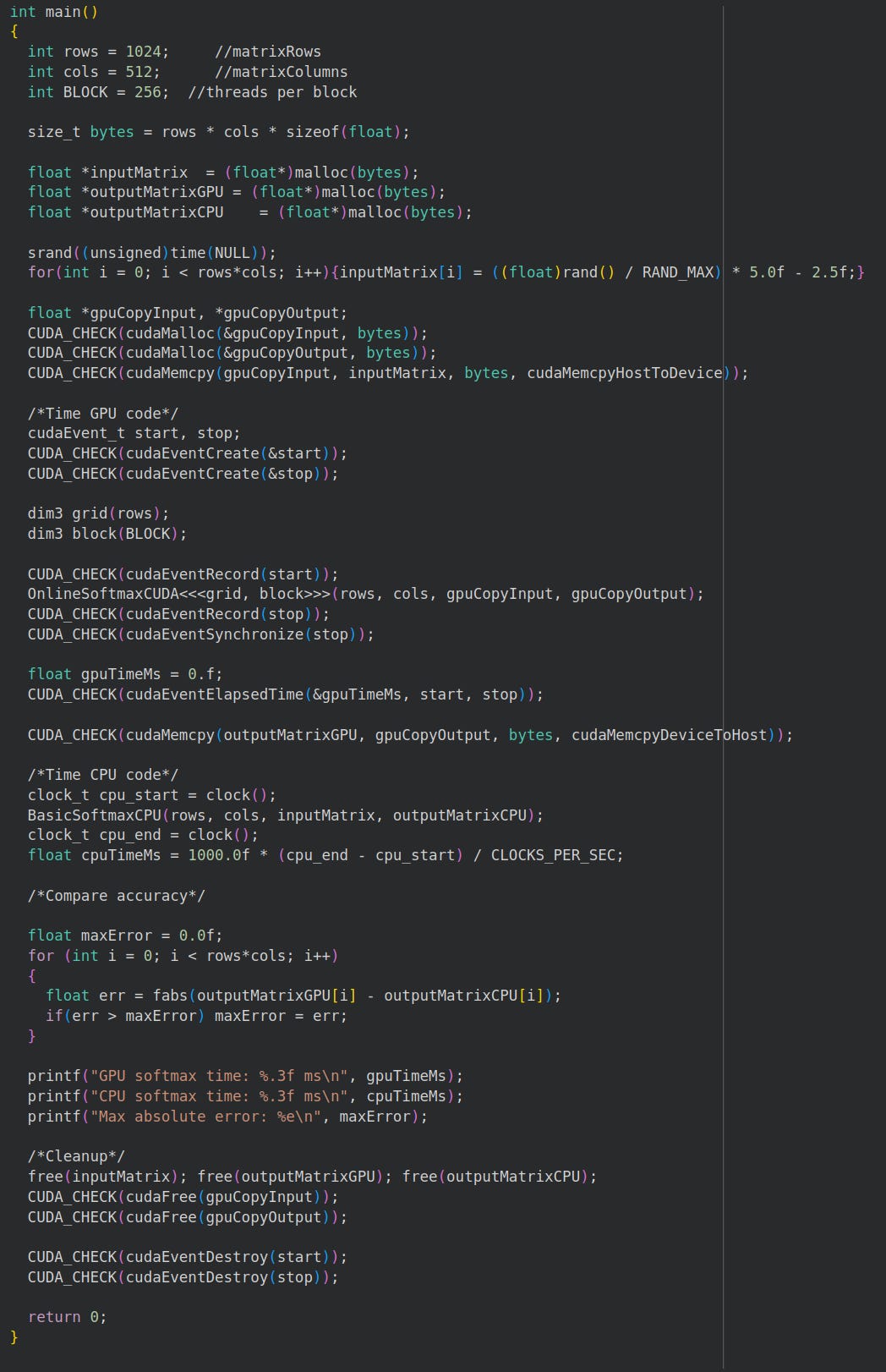
Next, we’ll write our main function. It’s a lot of CUDA boilerplate tbh.
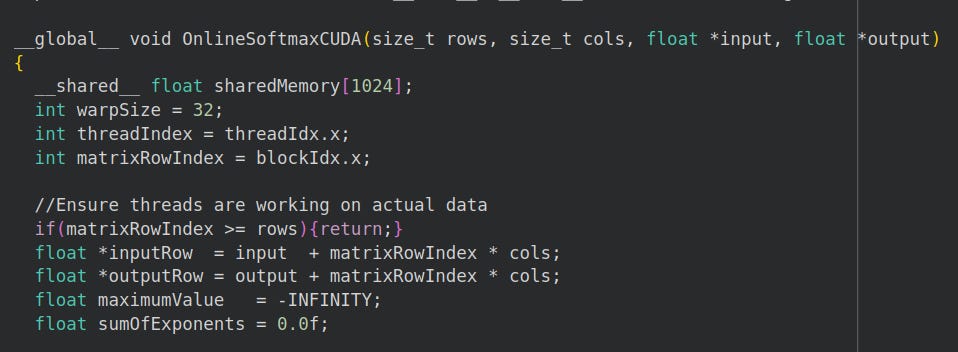
5.1 Understanding GPU Warps
We assign a block to each matrix row.
We assign a thread to each matrix column.
A warp is a group of GPU threads that execute the same instruction simultaneously, SIMD (Maharshi, 2025).
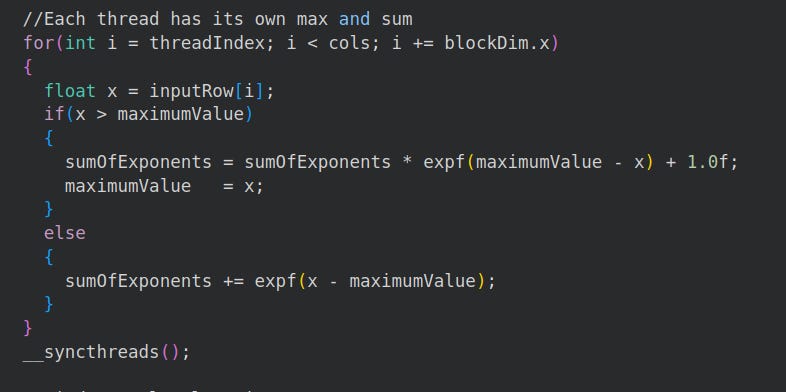
5.1.1 Finding Current Thread’s Max and Sum
For each thread we find the max and the sum like we did in #Section 4.
5.1.2 Finding Current Warp’s Max
Now we need to find the max and sum in the current warp (group of matrix columns).
CUDA provides the __shfl_down_sync, intrinsic for fast memory-sharing across warp registers.
*It’s faster to share memory across registers than in our __shared__ array
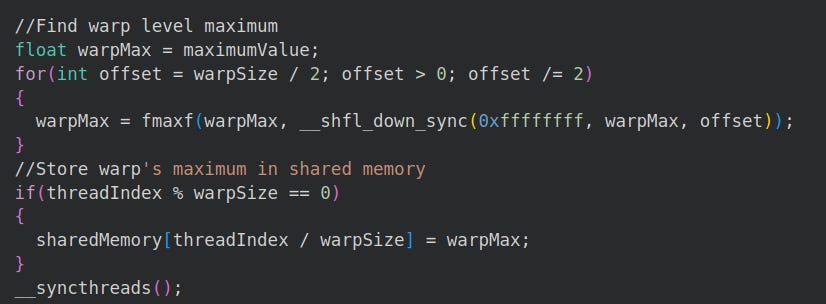
We store the warp maximum in our shared memory array for later.
5.1.3 Finding Current Block’s Max
Now that we have the warp maximum we can find the current block (matrix row) max.

Warp divergence occurs when we add if-else statements during warp execution and this slows things down (Venkatramana, 2025)5.
We write divergence-free code by using (? :) ternary operators instead of if-else statements since these compile to a single instruction (Venkatramana, 2025).
5.1.4 Finding Current Block’s Sum
We repeat #Section 5.1.1-5.1.3 to find the block-level sum.
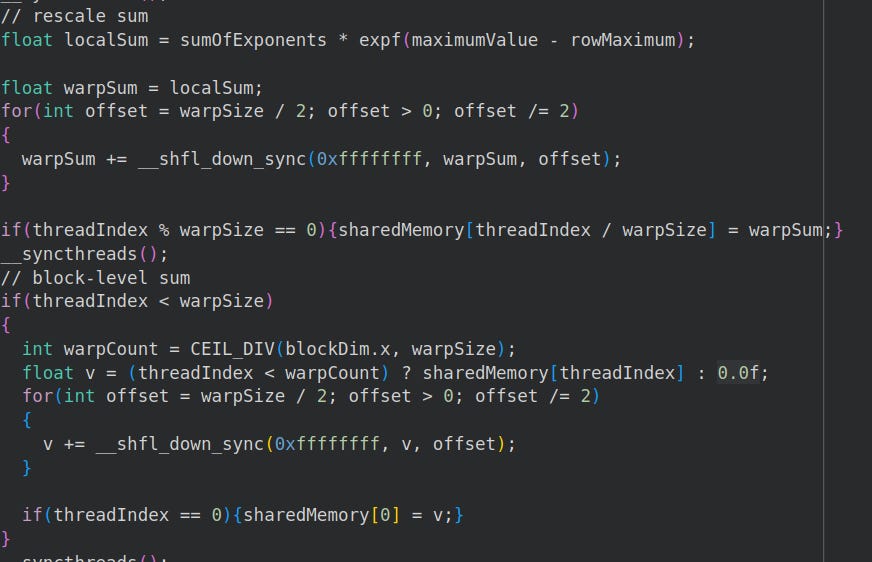
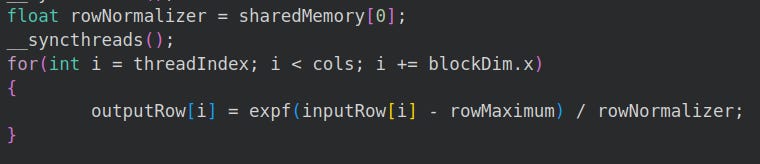
5.1.5 Softmax Calculation
Now, we have everything we need to compute a single row’s softmax.
6.0 CUDA vs CPU Results
These are our test variables:
int rows = 1024; //matrixRows
int cols = 512; //matrixColumns
int BLOCK = 256; //threads per blockThis means:
We’re finding 1024 different softmaxes.
Each softmax array has 512 elements.
Our blocks have 256 threads.
We use 256 threads to balance parallelism and sharedMemory usage (remember, sharedMemory is slower than registers)
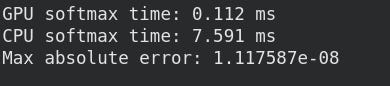
Our GPU code is 70 times faster than our CPU code!
The CPU and GPU should give similar results and we observe our code to be pretty accurate.
5.1 Further Reading
The original paper’s authors provide C++ style CUDA code (Nvidia GitHub, 2018)6 and a 1050Ti version (Maharshi, 2025)7 exists as well.
Here are some free gpu credits if you made it this far lol.
References
Milakov, M., & Gimelshein, N. (2018). Online normalizer calculation for softmax. arXiv preprint arXiv:1805.02867. https://arxiv.org/abs/1805.02867
Tianlong, S. (2025). Online Softmax. Tianlong’s Blog. https://tianlong312.github.io/blog/post-Online-Softmax/

