
Forward Forward Algorithm in Python
Training Neural Networks Without Backprop via Hinton's Forward Forward Algorithm

Quick Summary
We code the paper that introduced the Forward-Forward deep learning algorithm in Python.
Here are some free gpu credits.
Here’s 10 dollars off your next international transfer.
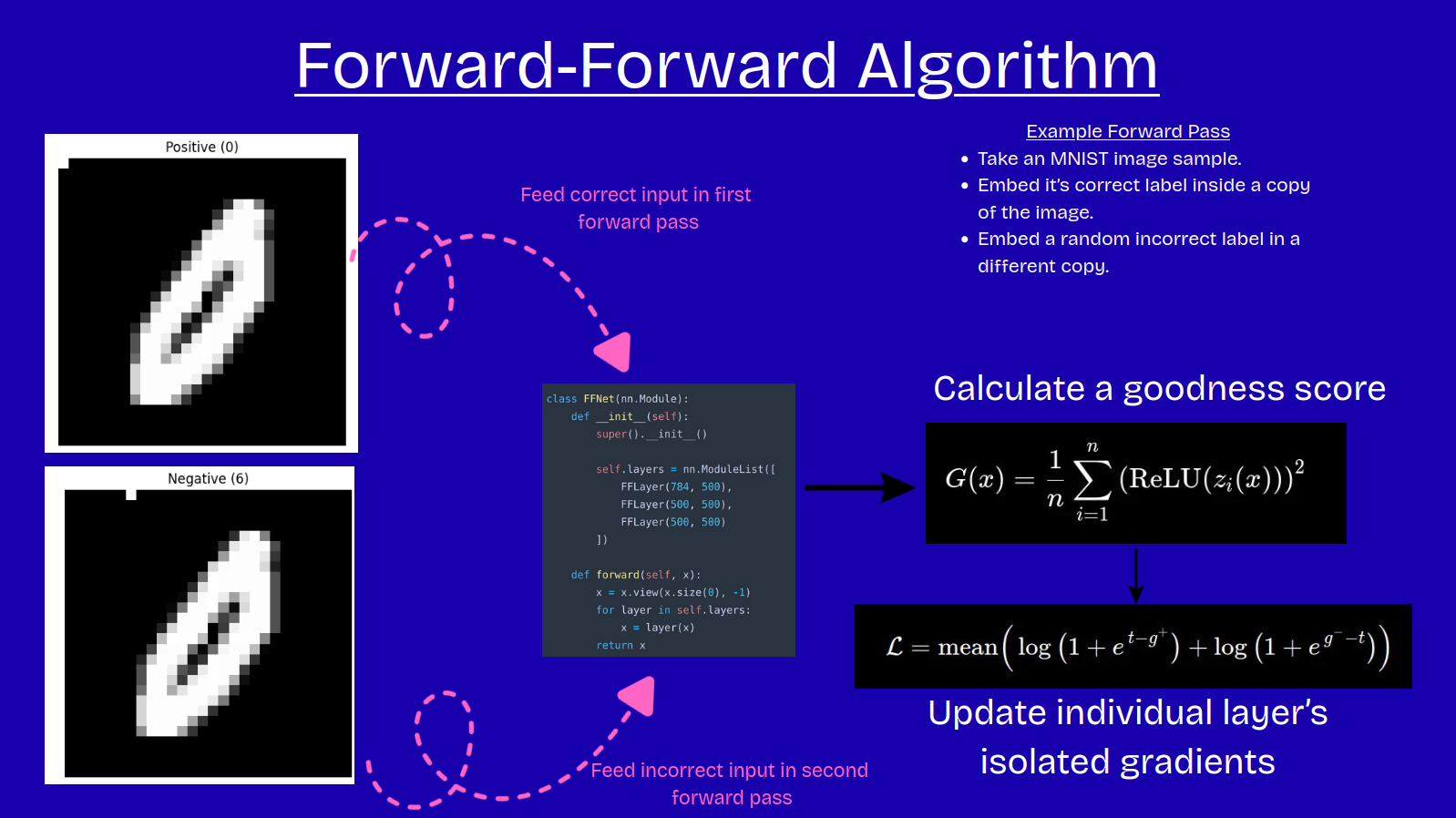
1.0 Paper Introduction
Forward-Forward (Hinton, 2022)1 is a biologically-plausible backpropagation alternative that achieves ~96% (Löwe, 2023)2 accuracy on MNIST without flowing gradients.

It vastly outperforms Target Propagation (Bengio, 2014)3, another biologically plausible backprop alternative, that reaches ~39% accuracy on MNIST.
This is the third part in our Alternatives To Backpropagation series:


1.1 Hinton’s Algorithm

Hinton’s idea is super simple: we run two forward passes. The first pass permits the network learn correct data points. The second pass is inundated with incorrect data to permit the network conceptualize false data*.
*It’s somewhat analogous to training a GAN that discriminates between good and bad inputs.
Each layer is trained in isolation (using gradient descent), so gradients don’t flow backwards through the network.
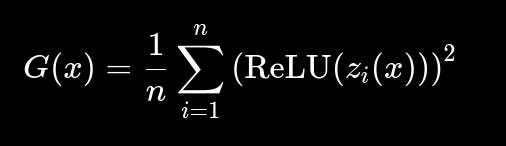
(Hinton, 2022) proposes goodness as a metric for measuring an individual layer’s ability to contrast correct and false data.
For correct inputs, each layer’s goodness should be above a certain threshold. For false inputs, goodness falls below the threshold.
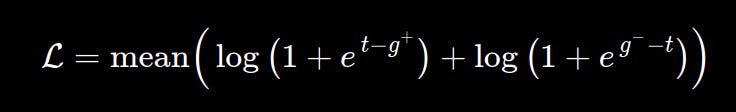
We train each layer in isolation to minimize the goodness loss function above.
Our network’s overall accuracy is the sum of total goodness.
2.0 Coding Forward-Forward
This section walks you through the Forward-Forward algorithm in Python. Code is available on GitHub. Here’s a YouTube summary:
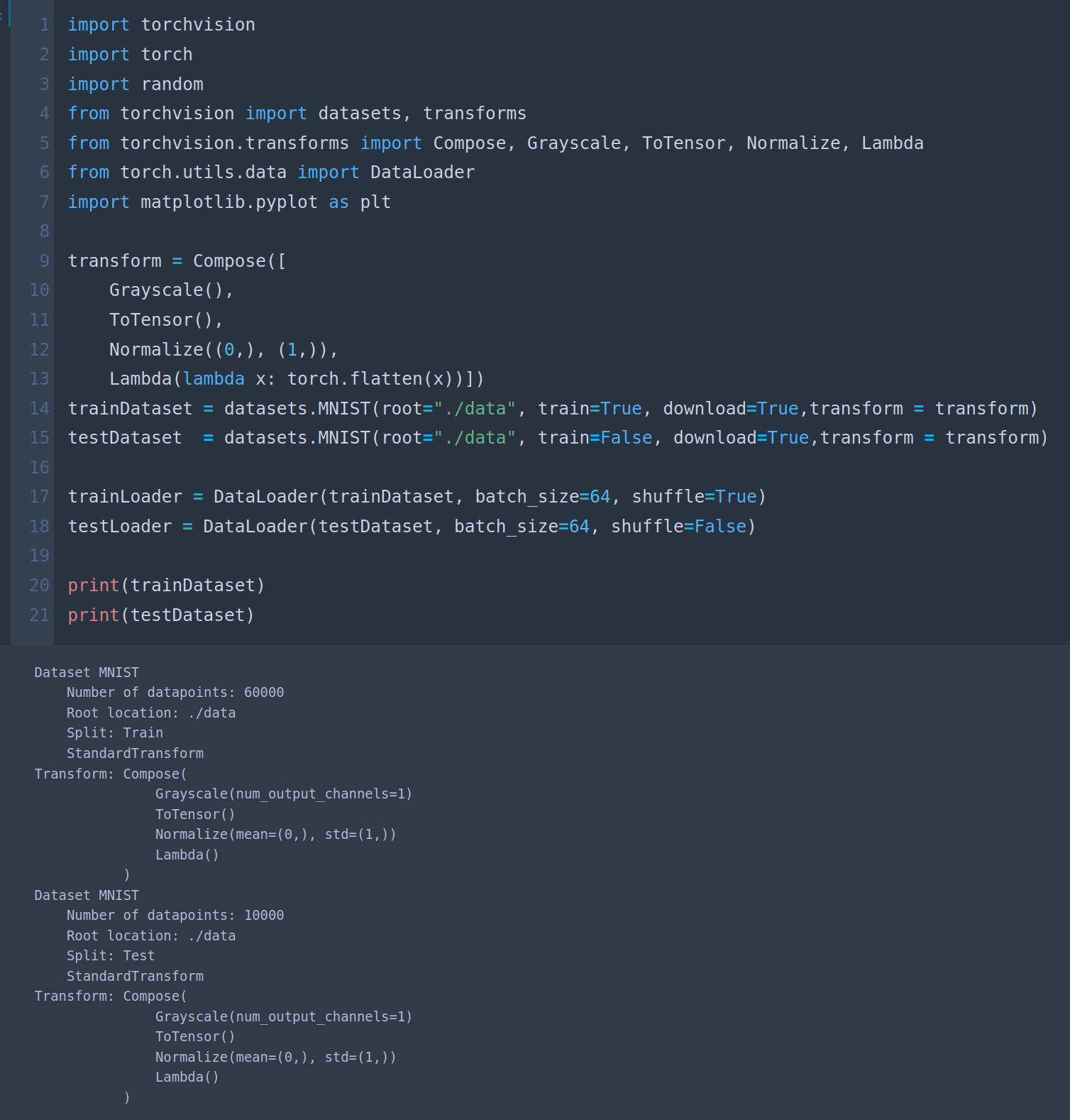
2.1 Loading MNIST
First, we load the MNIST dataset and split into train and test portions:
2.2 Data Labelling and Visualization
Next, we include a function to label each input. The LabelData function replaces the first 10 MNIST pixels with a one-hot encoded representation of the label:
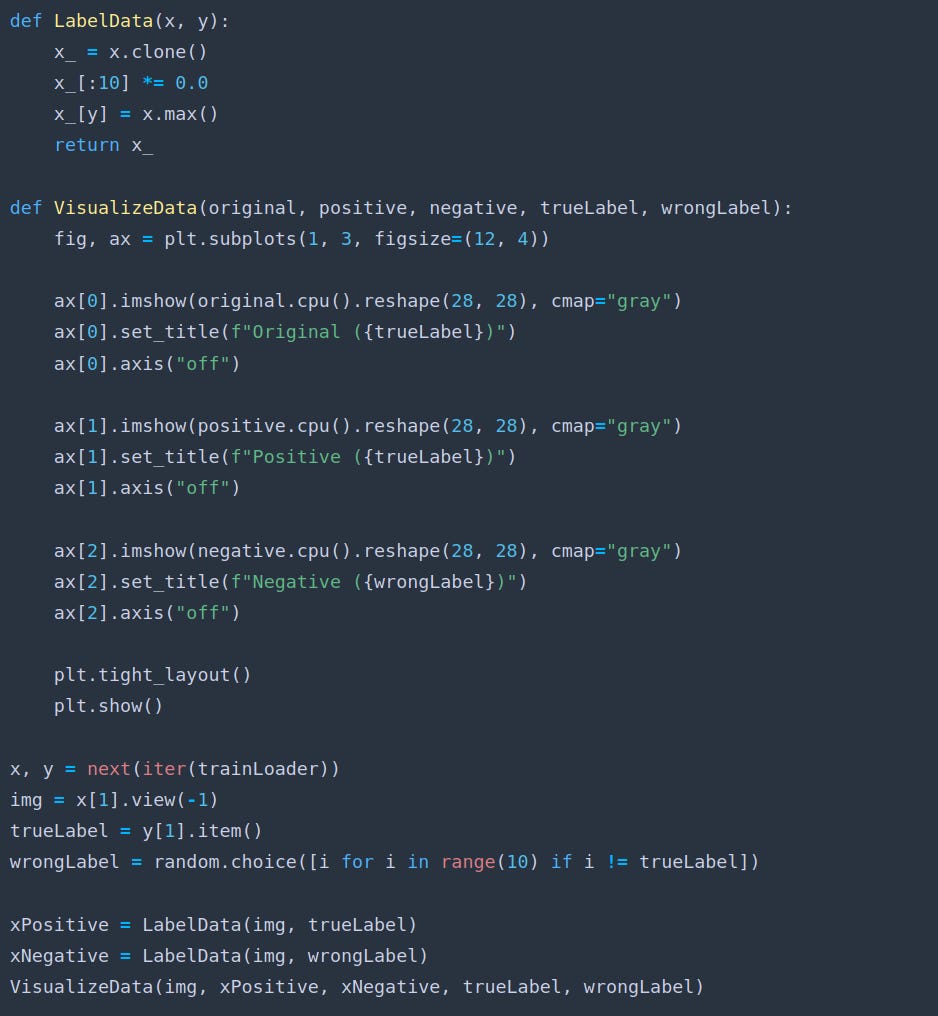
We run our visualize function to see:

Observe the white square in the top-left corner of xPositive and how it’s incorrectly placed in xNegative.
2.3 Linear Layers Activated by ReLU

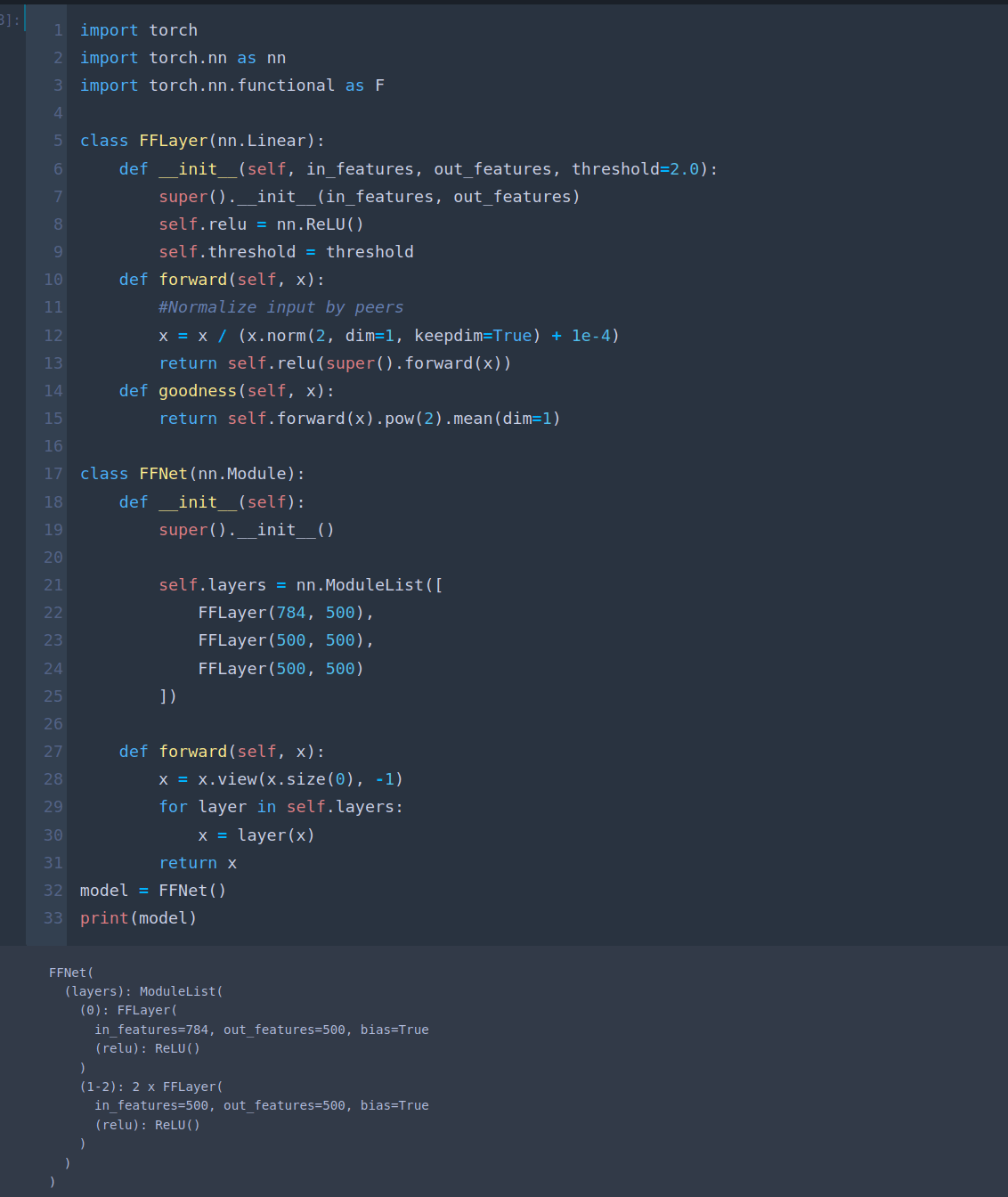
Next, we define our linear layers, each activated by ReLU. We follow the normalization suggestion given in (Hinton, 2022).
2.4 Training Step
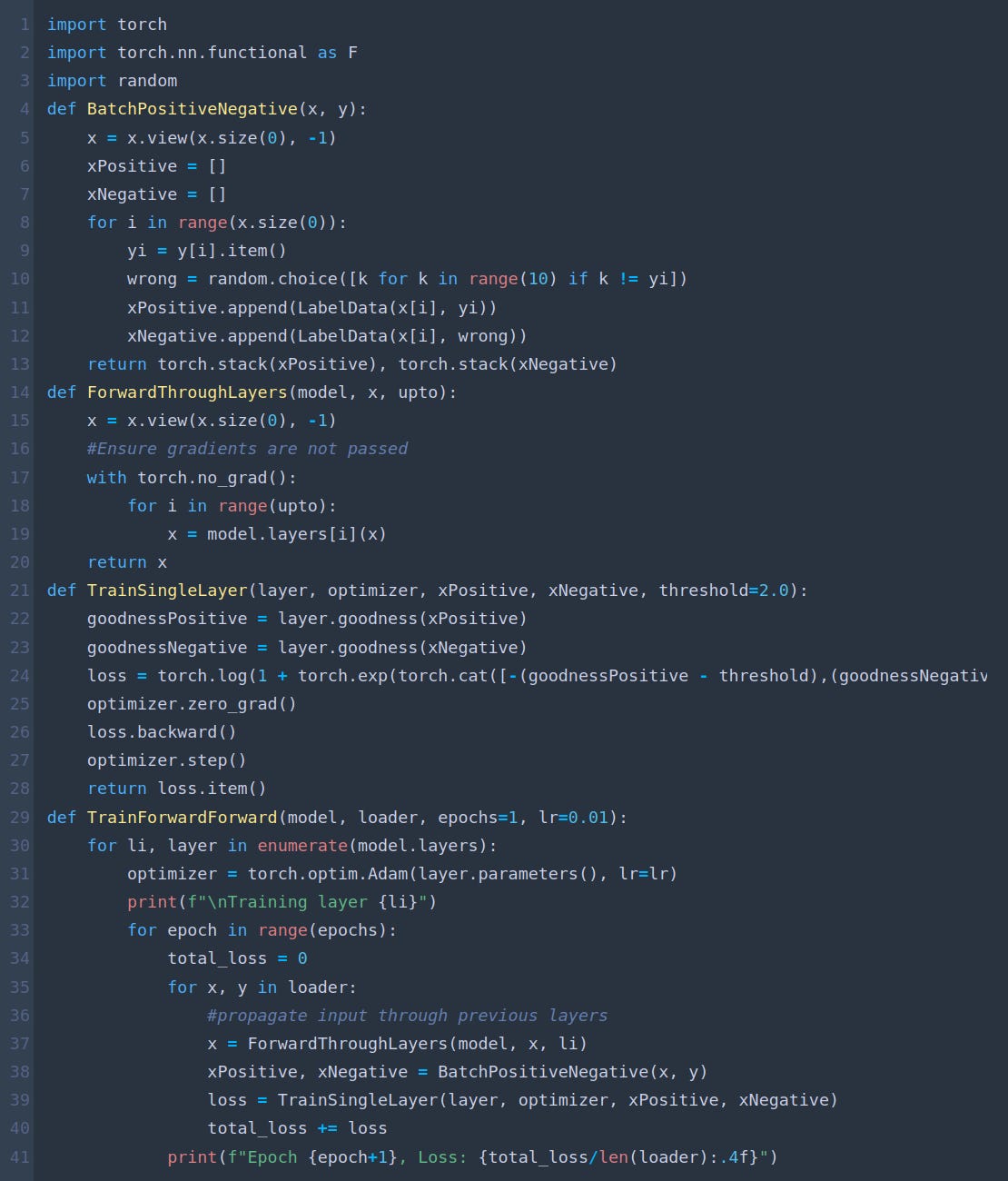
Next, we write our TrainForwardForward function. We pass the input through each layer in phases.
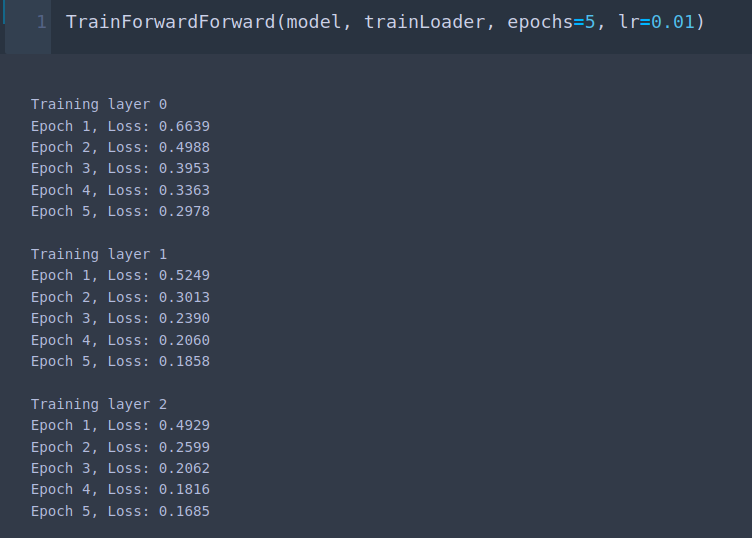
We run our network to observe each layer being trained in isolation:
2.5 Prediction and Accuracy
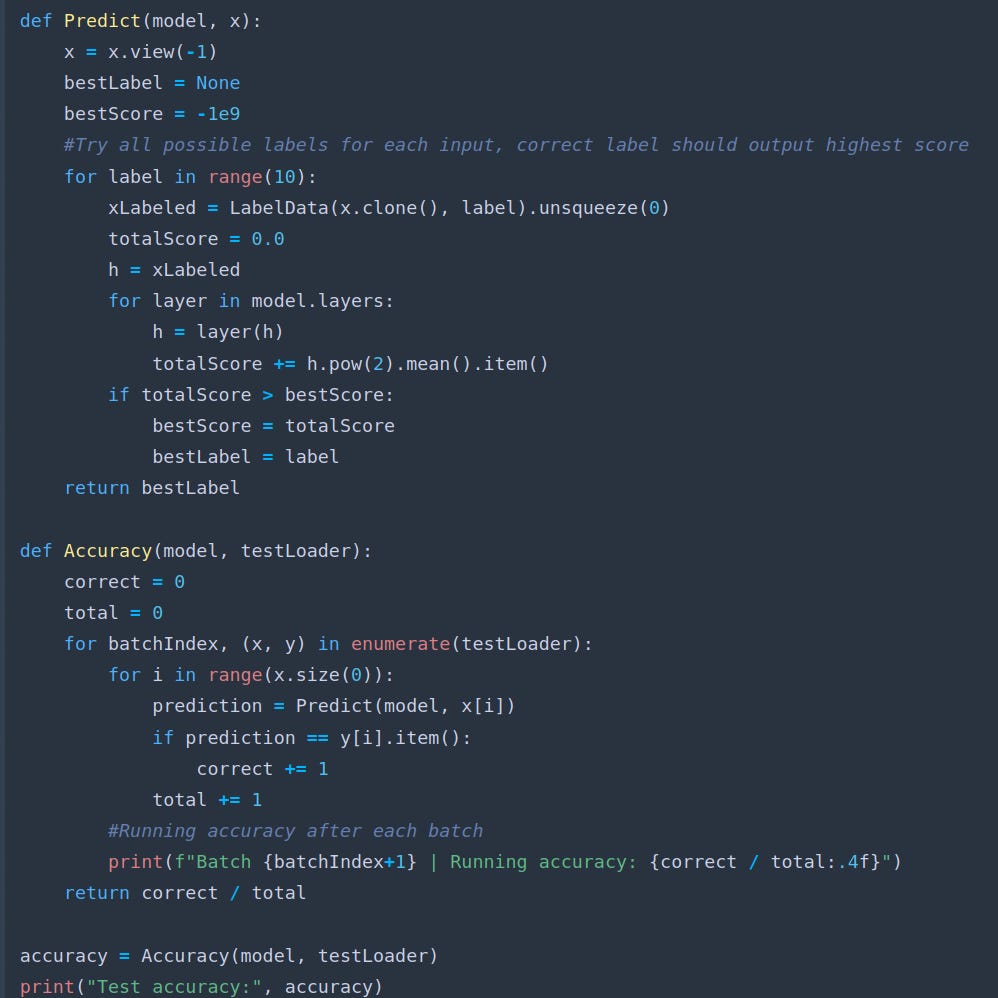
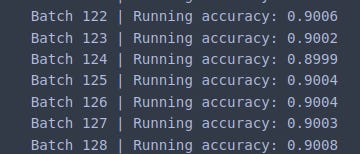
Our implementation achieves ~89% accuracy on individual batches.
We made it through the paper! You might also like:
and
References
Hinton, G,. (2022). The Forward-Forward Algorithm: Some Preliminary Investigations. ArXiv. https://doi.org/10.48550/arXiv.2212.13345
Löwe, S. (2023). Forward-Forward. GitHub repo.
Bengio, Y,. (2014). How Auto-Encoders Could Provide Credit Assignment in Deep Networks via Target Propagation. ArXiv. https://doi.org/10.48550/arXiv.1407.7906