

Quick Summary
We code the Discrete Diffusion Model paper that won ICML 2024. These models demonstrate that denoising each token’s probability vector works better than denoising individual tokens.

1.0 Paper Introduction
The paper Discrete Diffusion Modeling by Estimating the Ratios of the Data Distribution (Lou et al., 2024)1 introduces score entropy, a custom loss function for text diffusion models that extends score matching to discrete spaces.

The authors further introduce Score Entropy Discrete Diffusion (SEDD) models to demonstrate their thesis: denoising each token’s probability vector works better than denoising individual tokens (Letitia, 2024)2.
We code the paper in C (just to feel something). A Python version is provided by the paper’s author*(Louaaron, 2024)3 as well as (Ash80, 2025)4.
*The first author (Aaron Lou) is OpenAI’s Head of Strategic Exploration. What if a text diffusion ChatGPT is in the books?
1.1 Related Work
This is part of our Stable Diffusion from Scratch series where we’ve encountered different diffusion architectures: SORA’s Diffusion Transfomer, Denoising Diffusion Probabilistic Models (DDPMs)5, Denoising Diffusion Implicit Models (DDIMs)6, Optimization Perspective Diffusion Models (OPDMs)7 and Stochastic Differential Equation8 models.
We code the inference section of this paper so it’s just like the diffusion models we encountered before.
2.0 Getting Started
Code is available on GitHub.
We start from the Safetensors parsers we wrote alongside this saved model checkpoint.

The model outline is given below. However, note that the block labelled Transformer is in fact a Discrete Diffusion block.
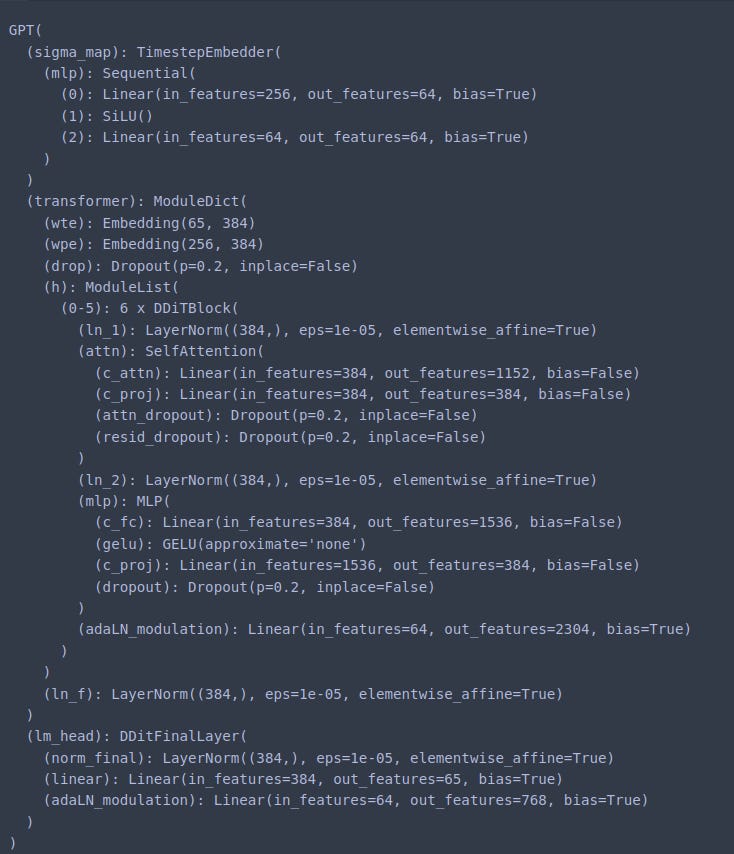
2.1 Helper Functions
Next, we write super basic matrix operations that align with Pytorch’s conventions:
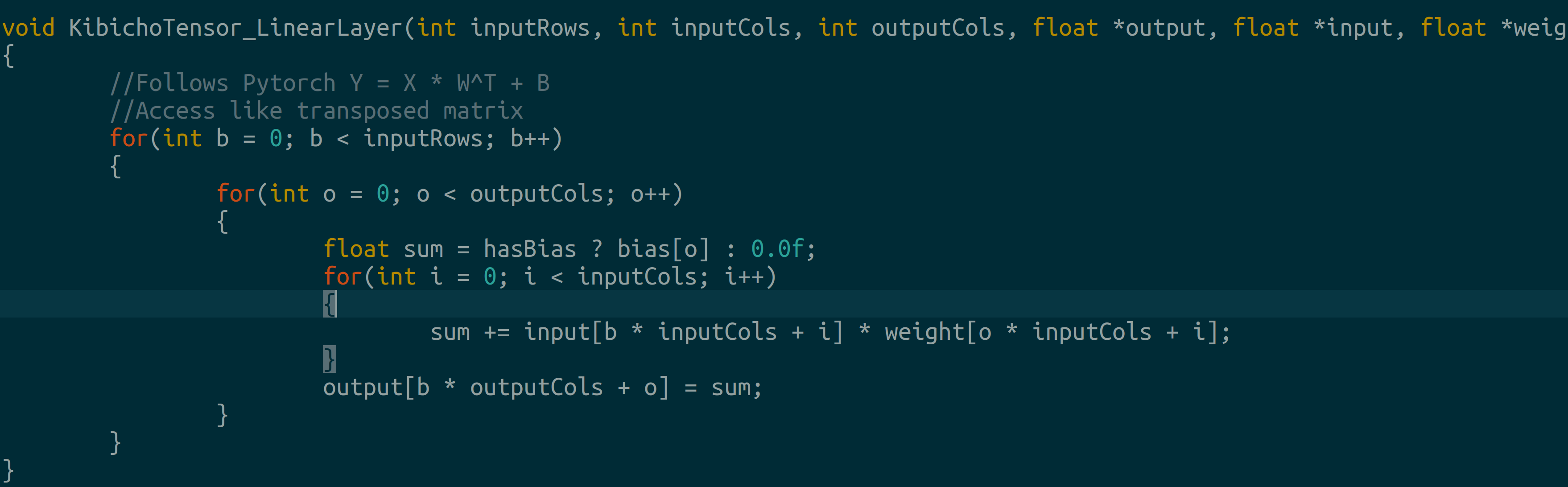
Linear Layer: Pytorch implements this as Y=X*WT+B where W is the raw safetensor weight and B is the bias. In C, it resembles:
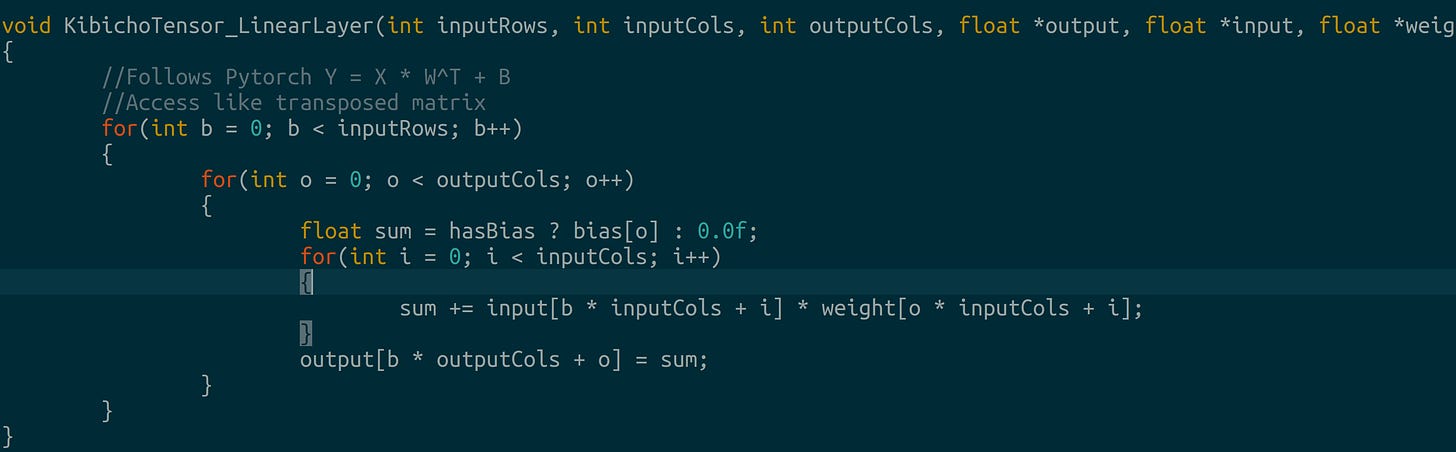
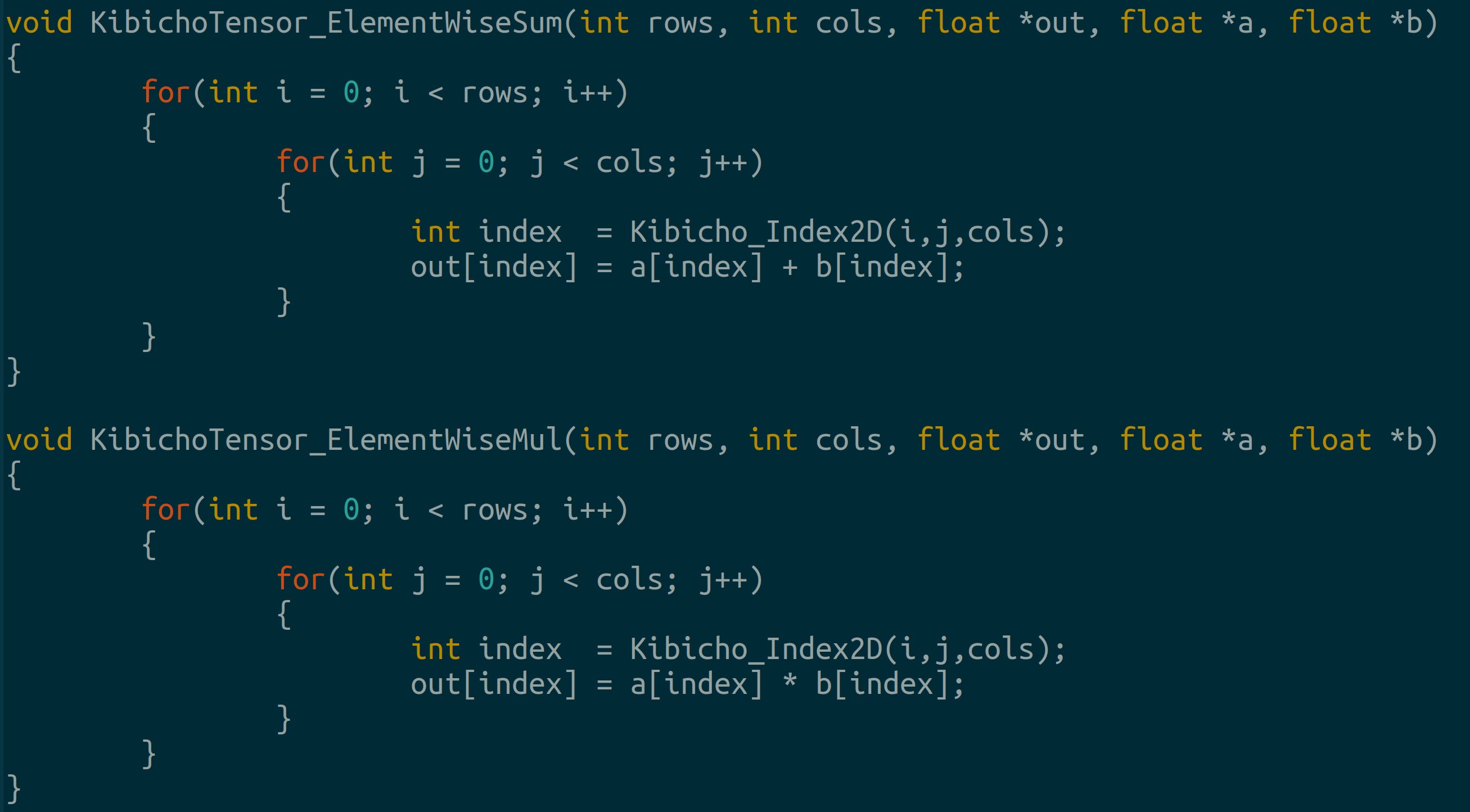
Custom linear layer in C Hadamard Sum and Product: These are element-wise addition and multiplication:
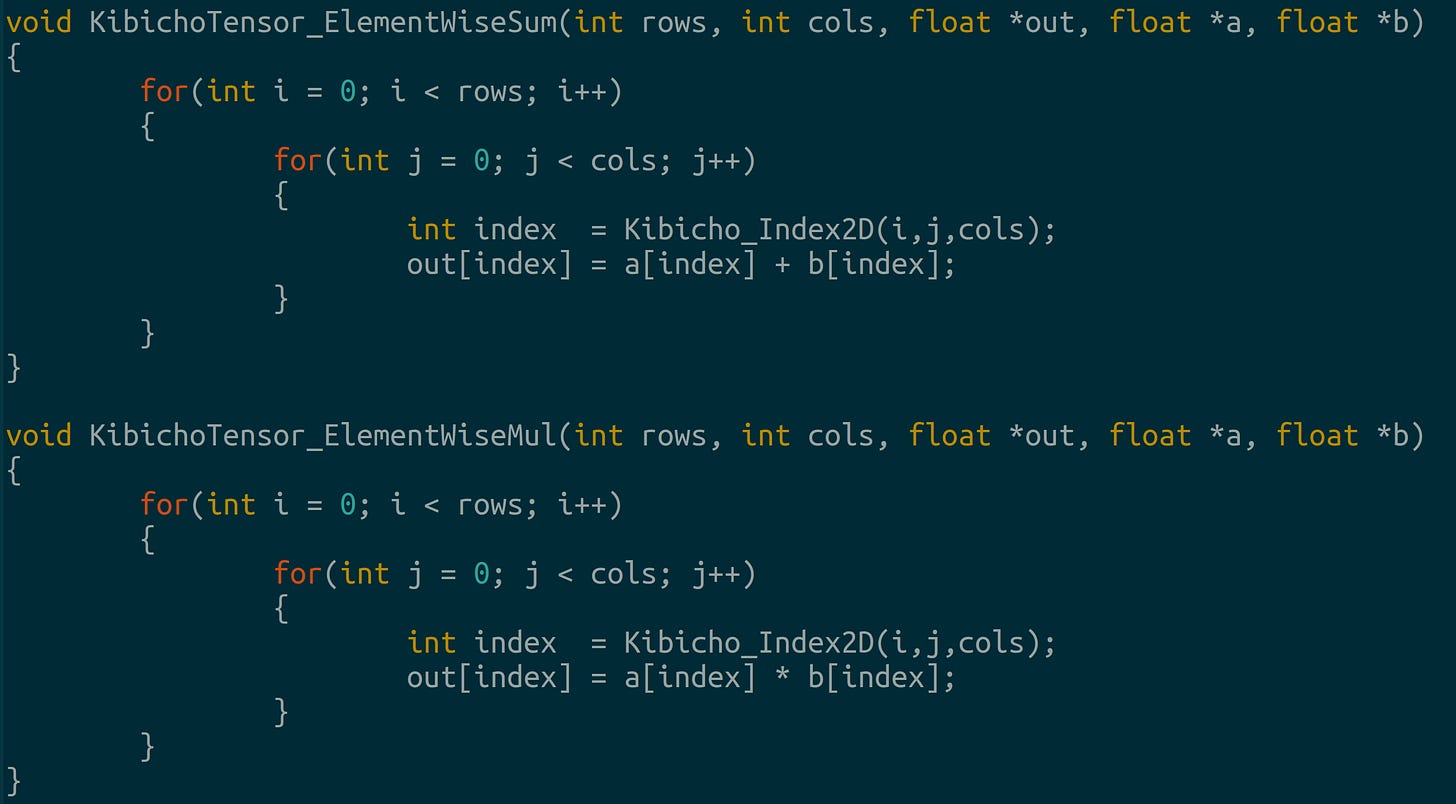
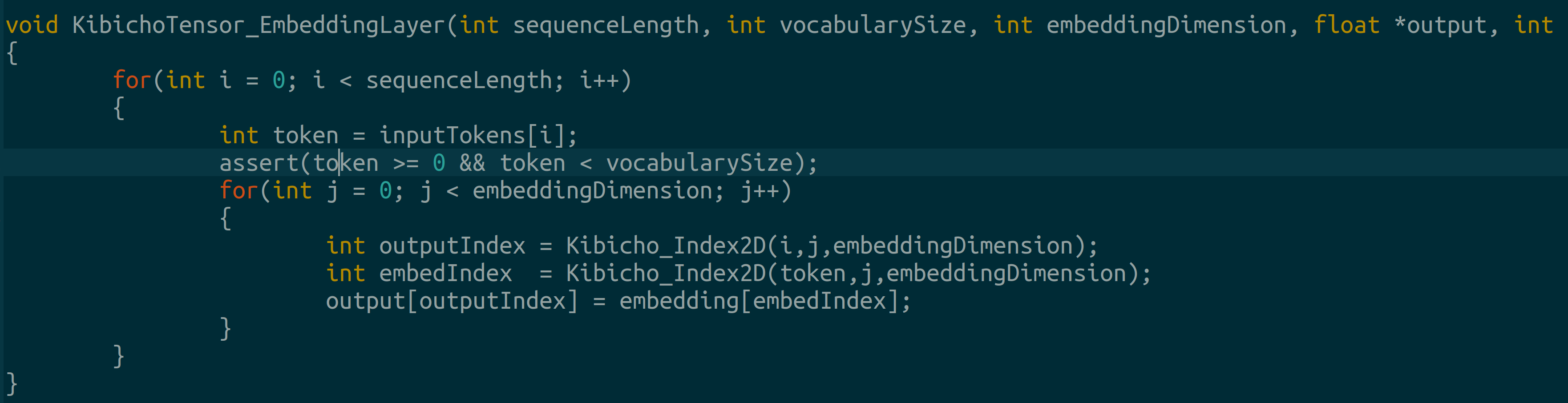
Element-wise addition and multiplication Embedding layer: TIL embedding layers are lookup tables.
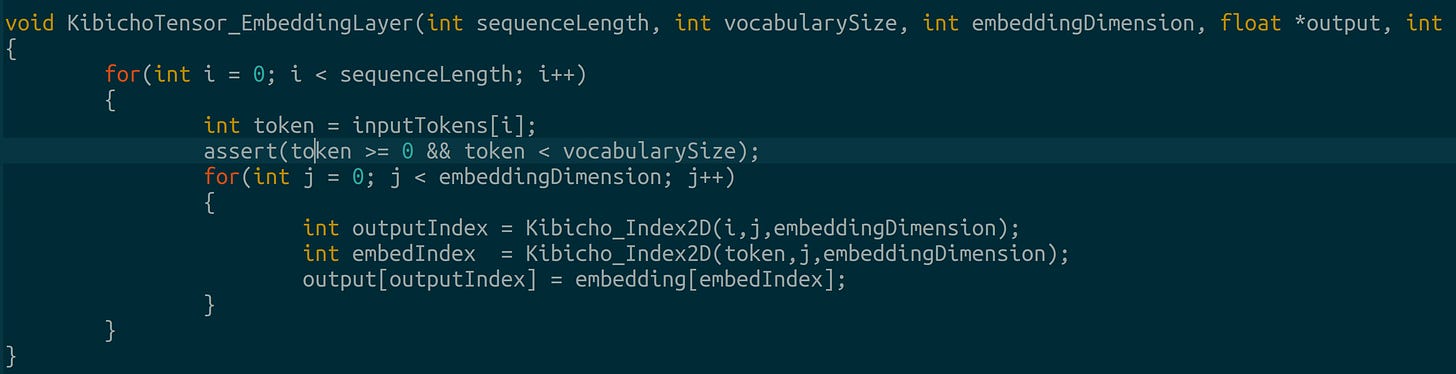
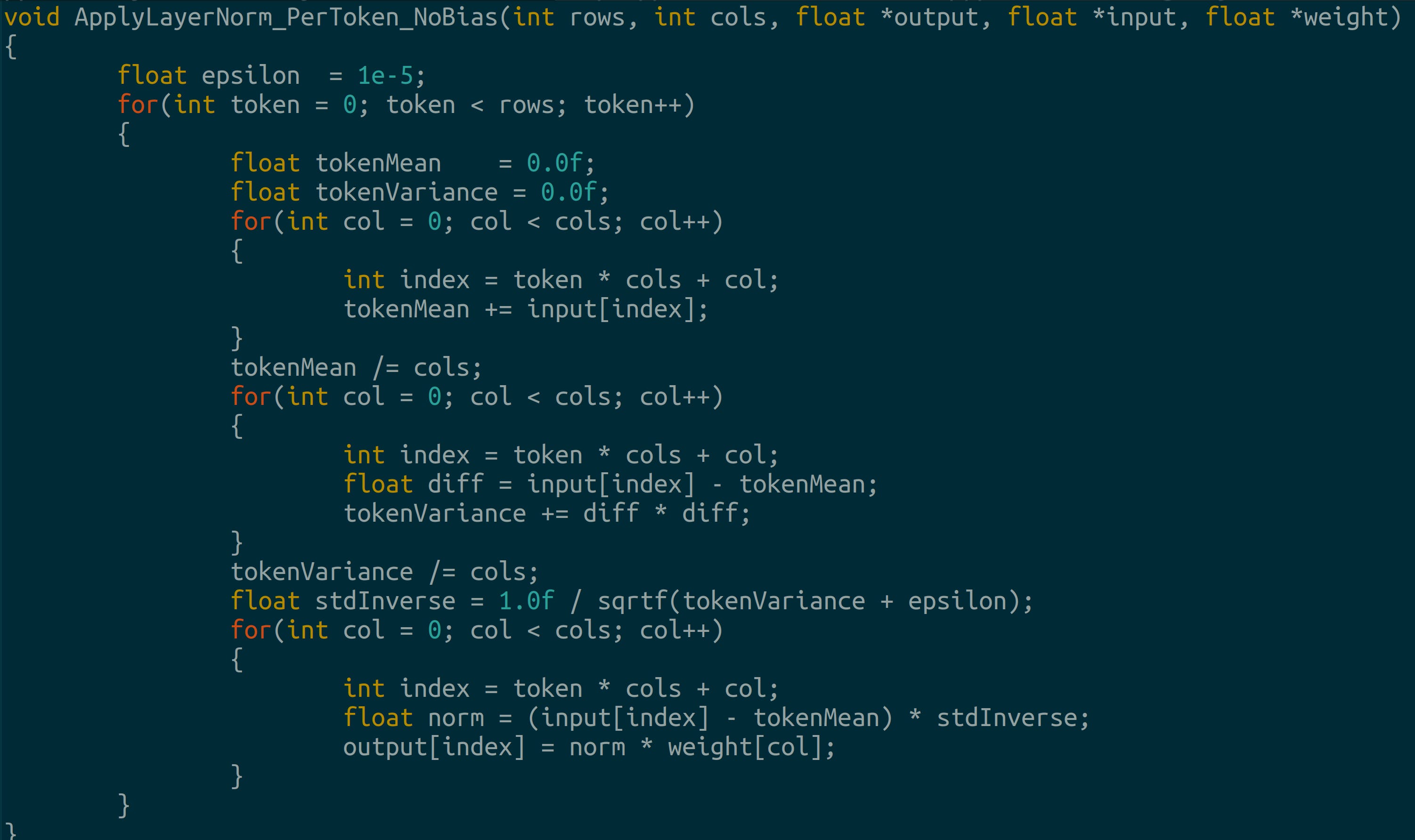
Embedding layer implemented as a lookup table Layer normalization: Discrete diffusion models appear to work faster, and demonstrate higher accuracy when layer norm is done per token, with zero bias (Colab Annotated Diffusion Model, 2024)9
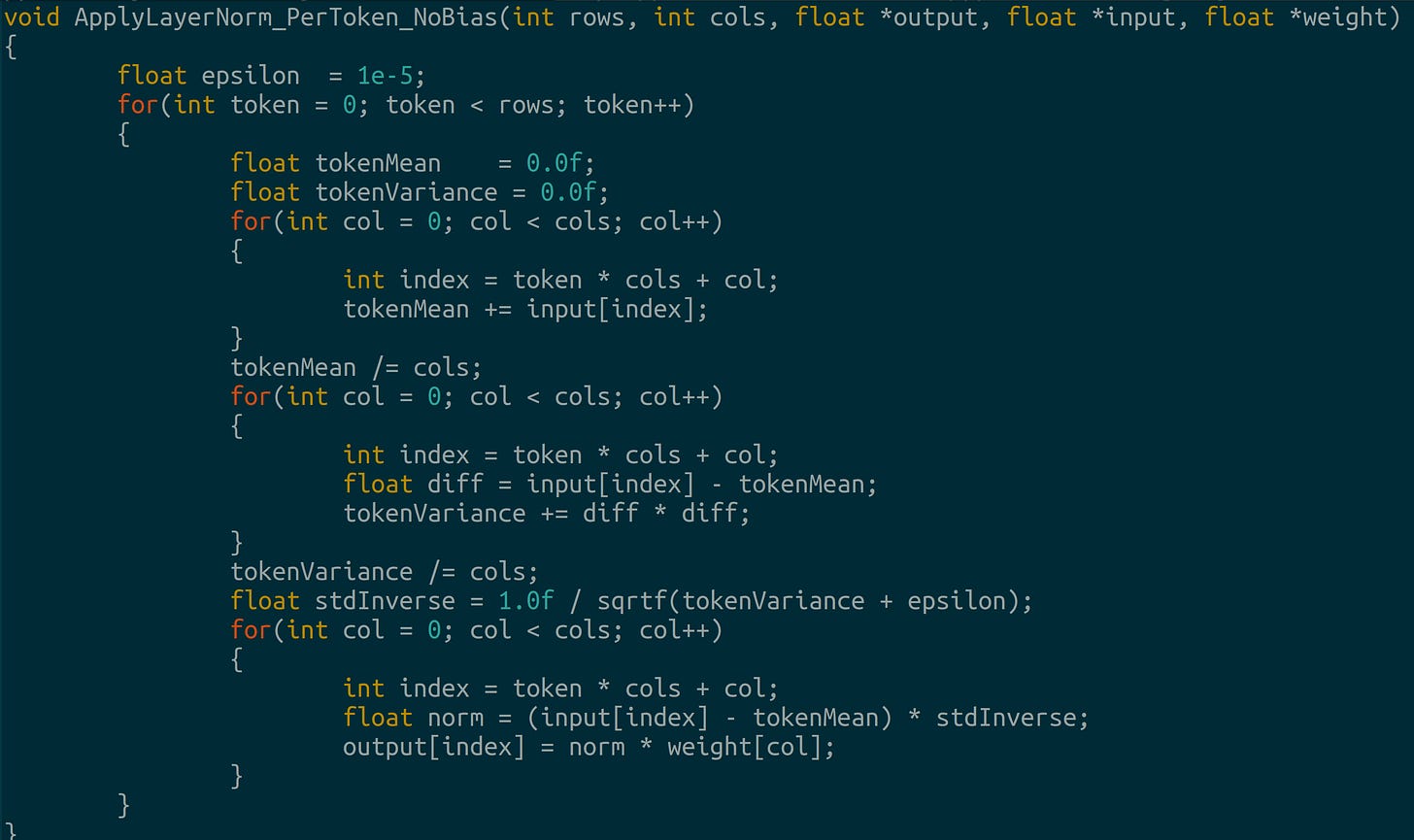
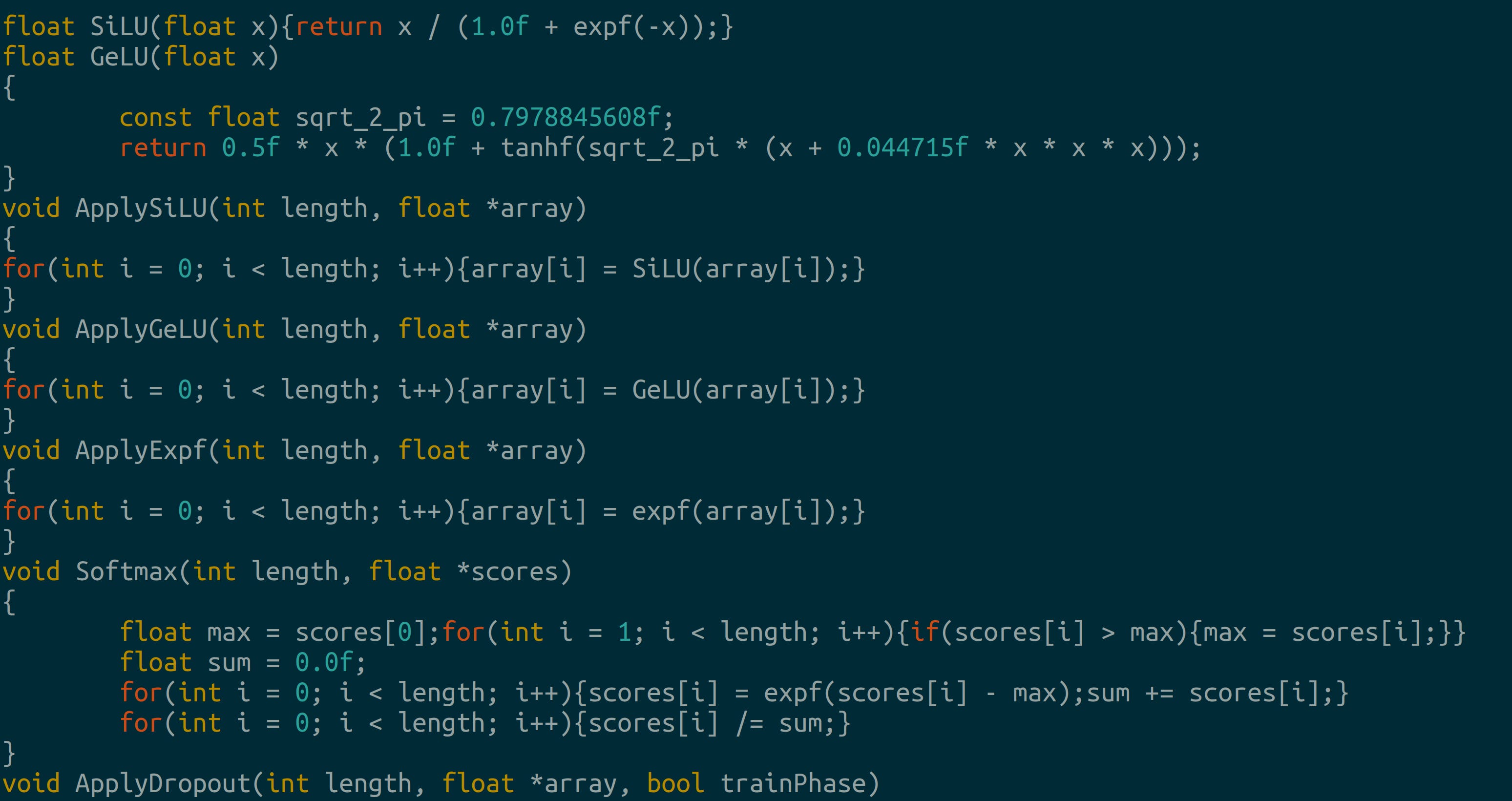
Layer norm without bias Activations and regularization: The authors use SiLU and GeLU in the layers, softmax appears in attention and dropout prevents overfitting during training.
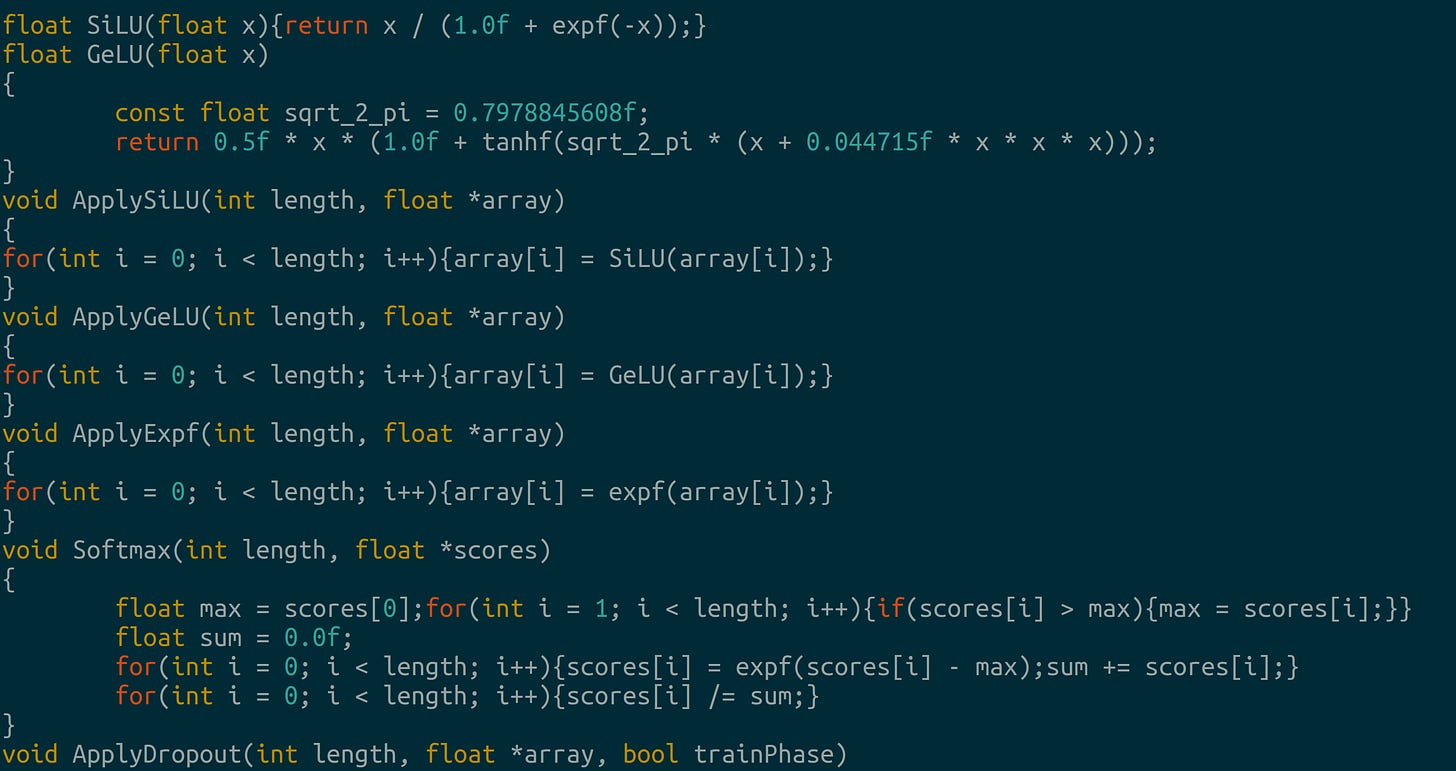
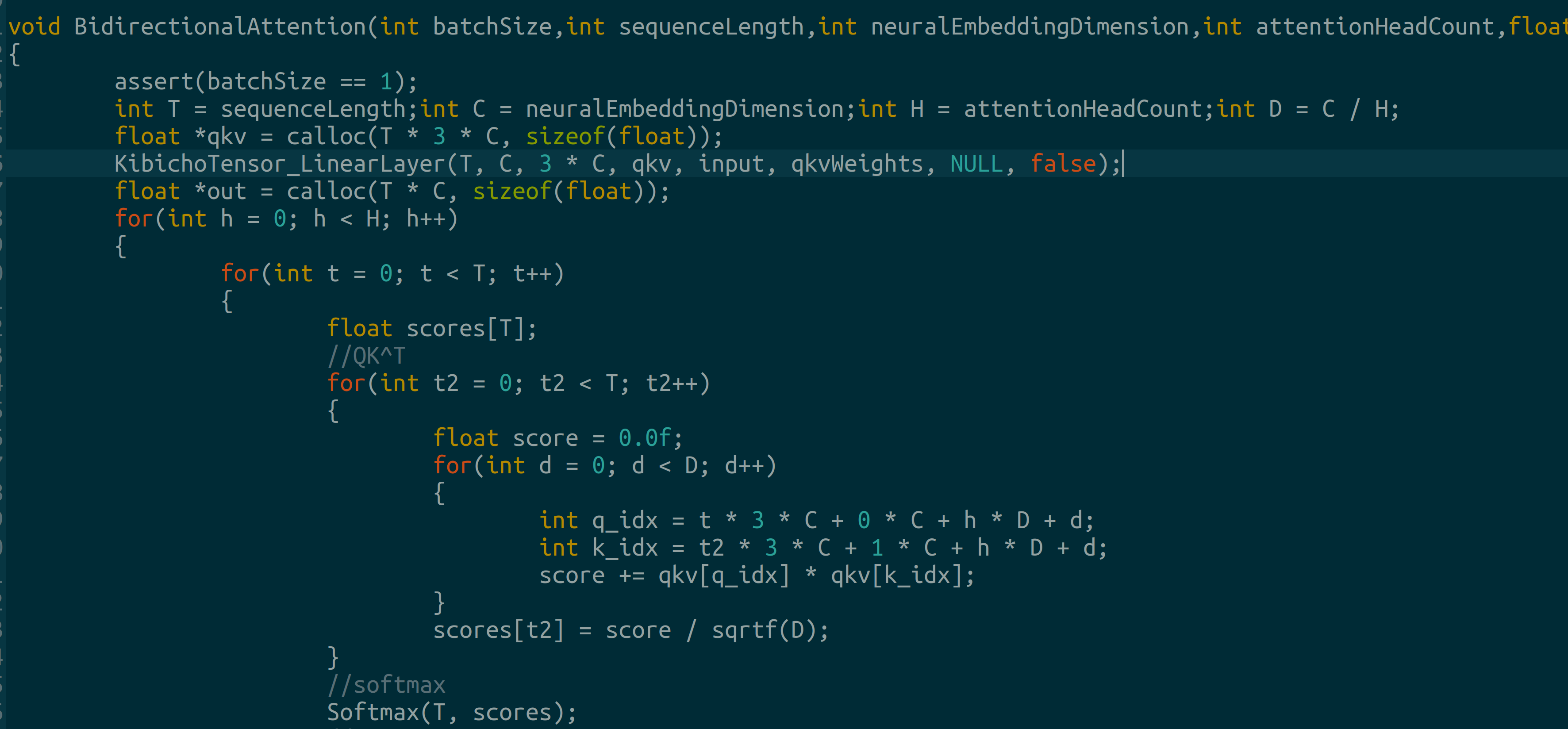
SiLU, GeLU, softmax and dropout Bidirectional Attention: Discrete diffusion implements attention without causal masks so the model can see preceding and incoming tokens:
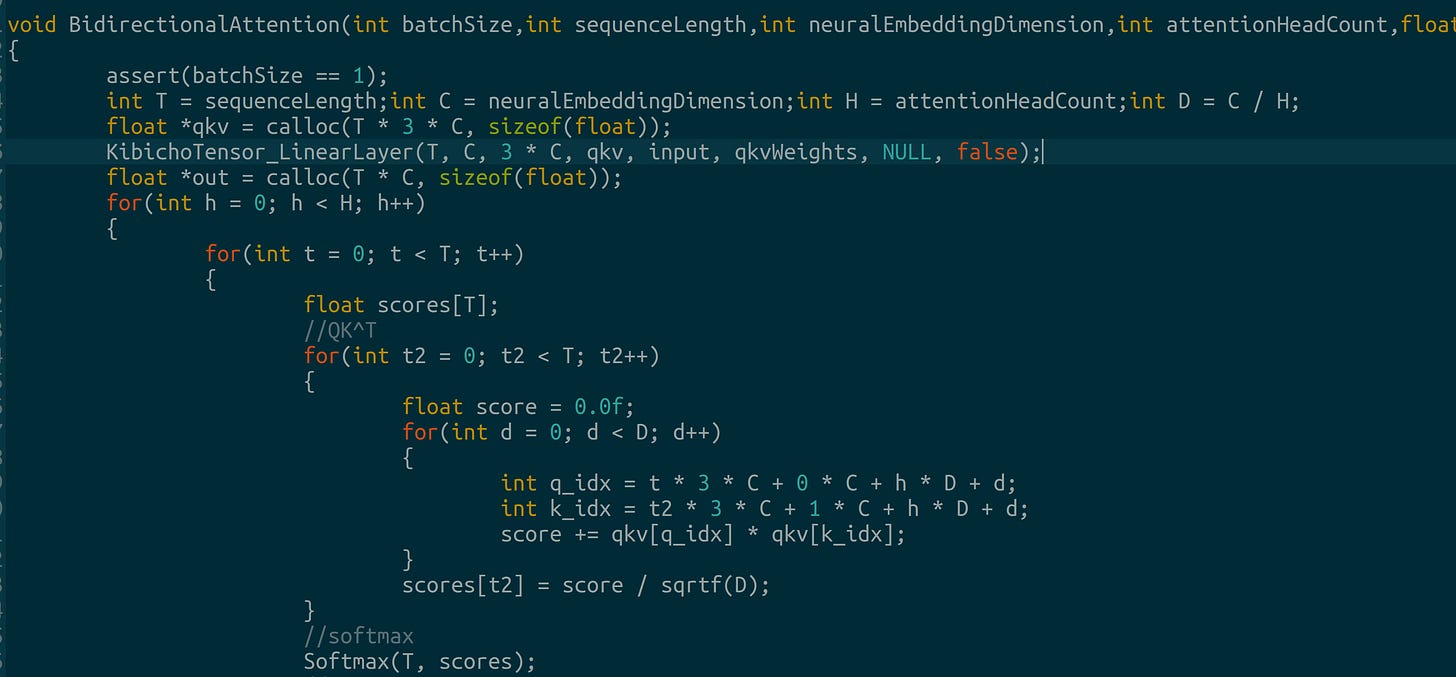
Bidirectional attention without masks Categorical sampling: we use Gumbel-max to find the next inputs to our model once we generate probabilities:
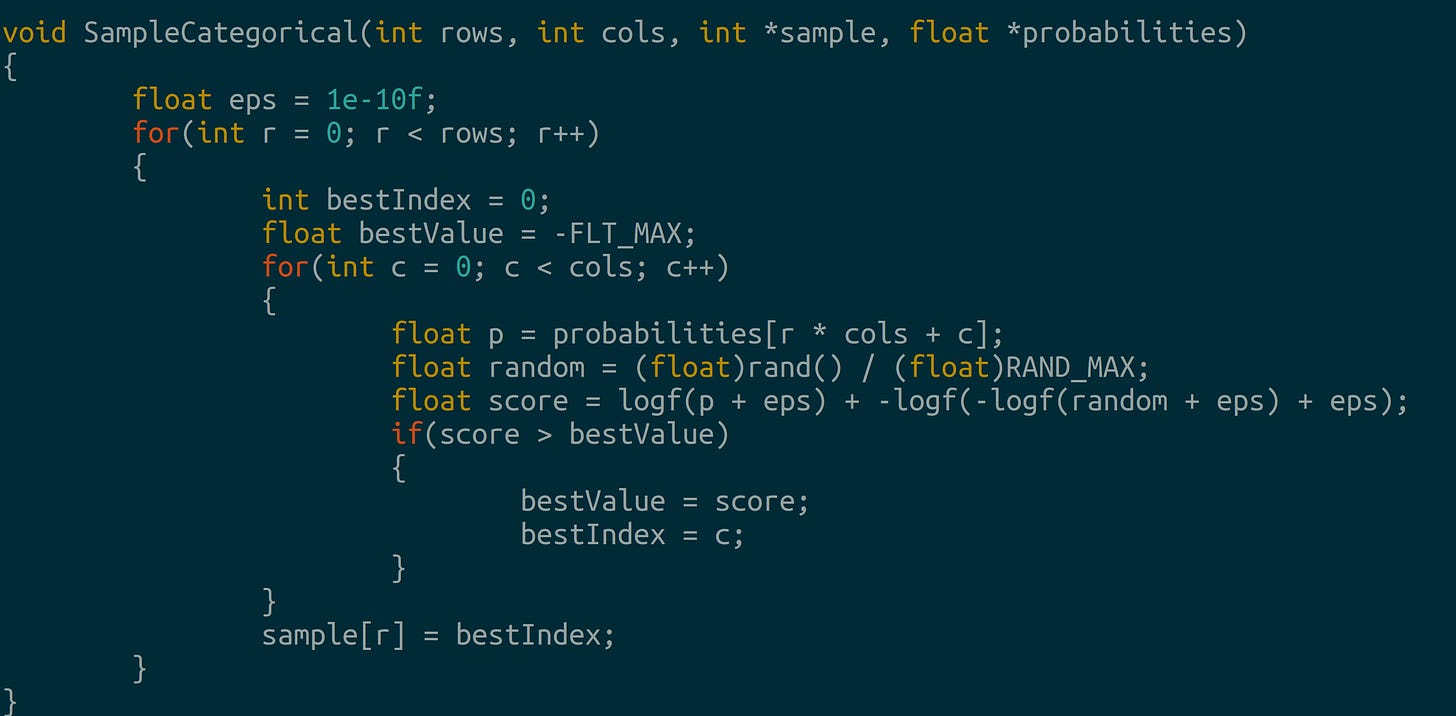
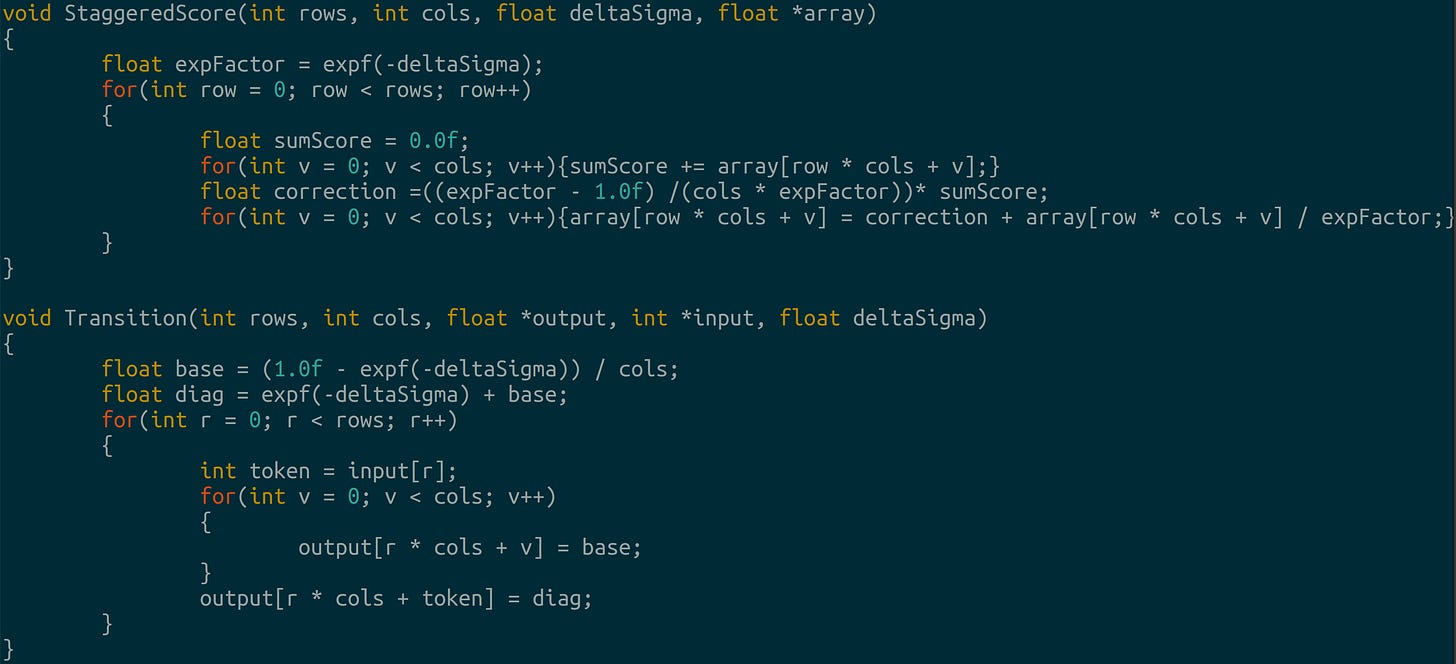
Categorical sampling with gumbel-max Transition matrices and scoring: we use a uniform rate matrix to transition between tokens and apply the inverse operator from before:
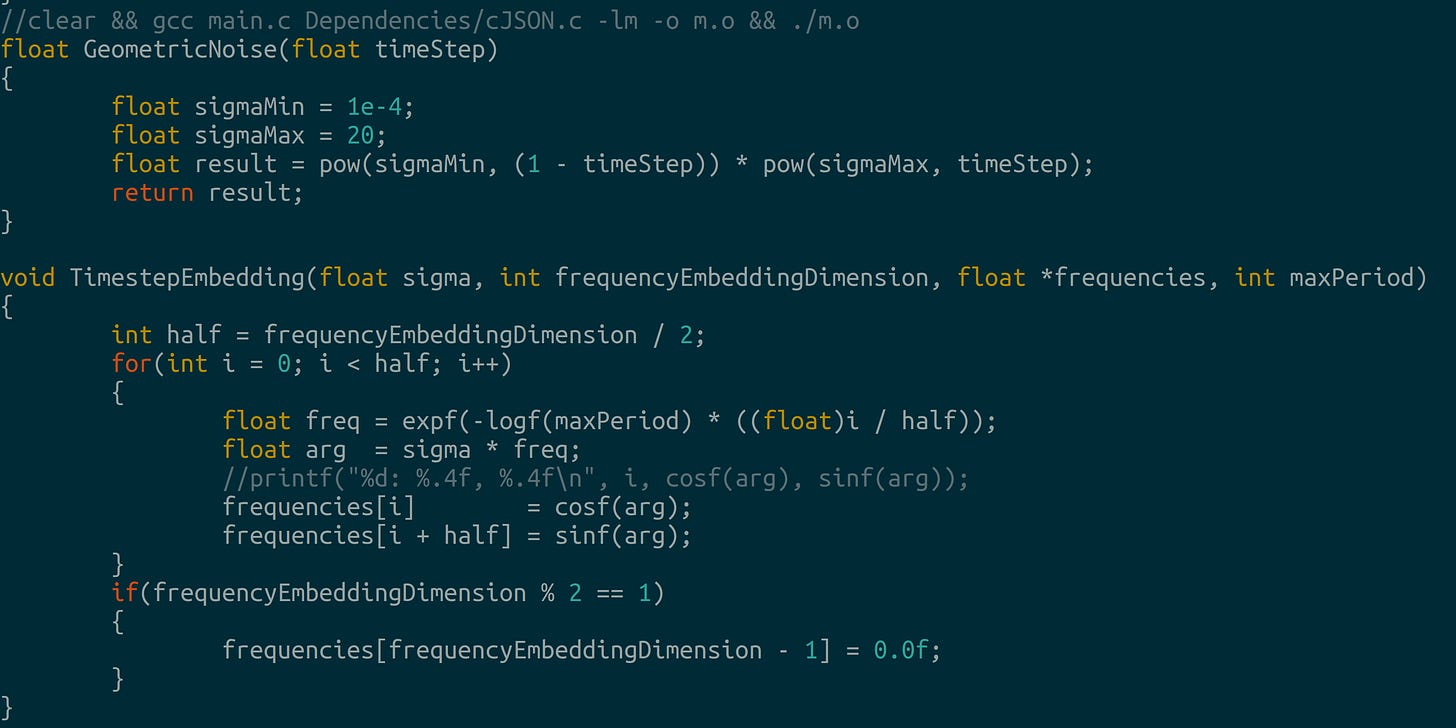
Scoring and transition matrices Noise generator and position embeddings: we use geometric noise and sinusodial embeddings:
Noise and position embeddings
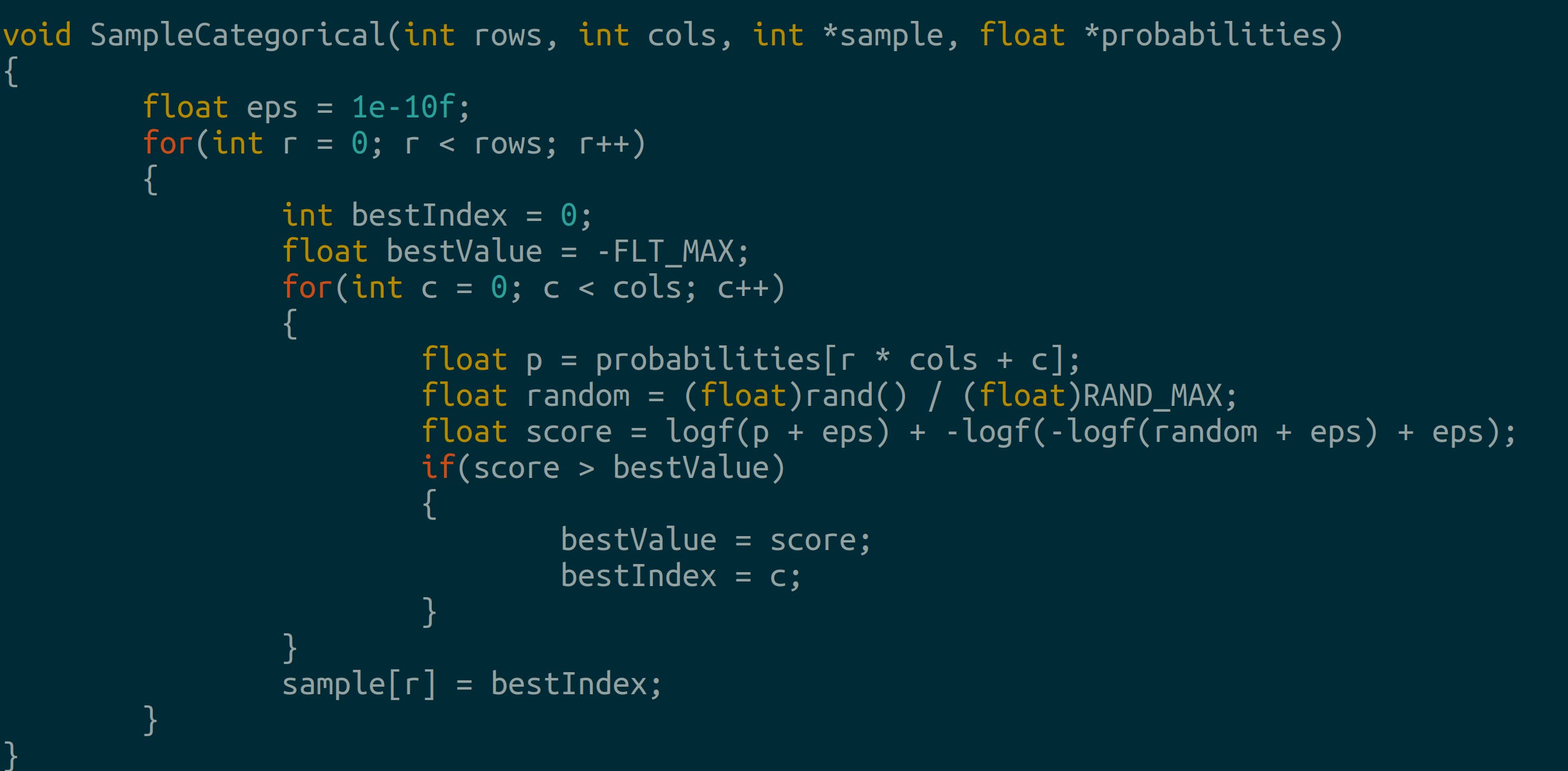
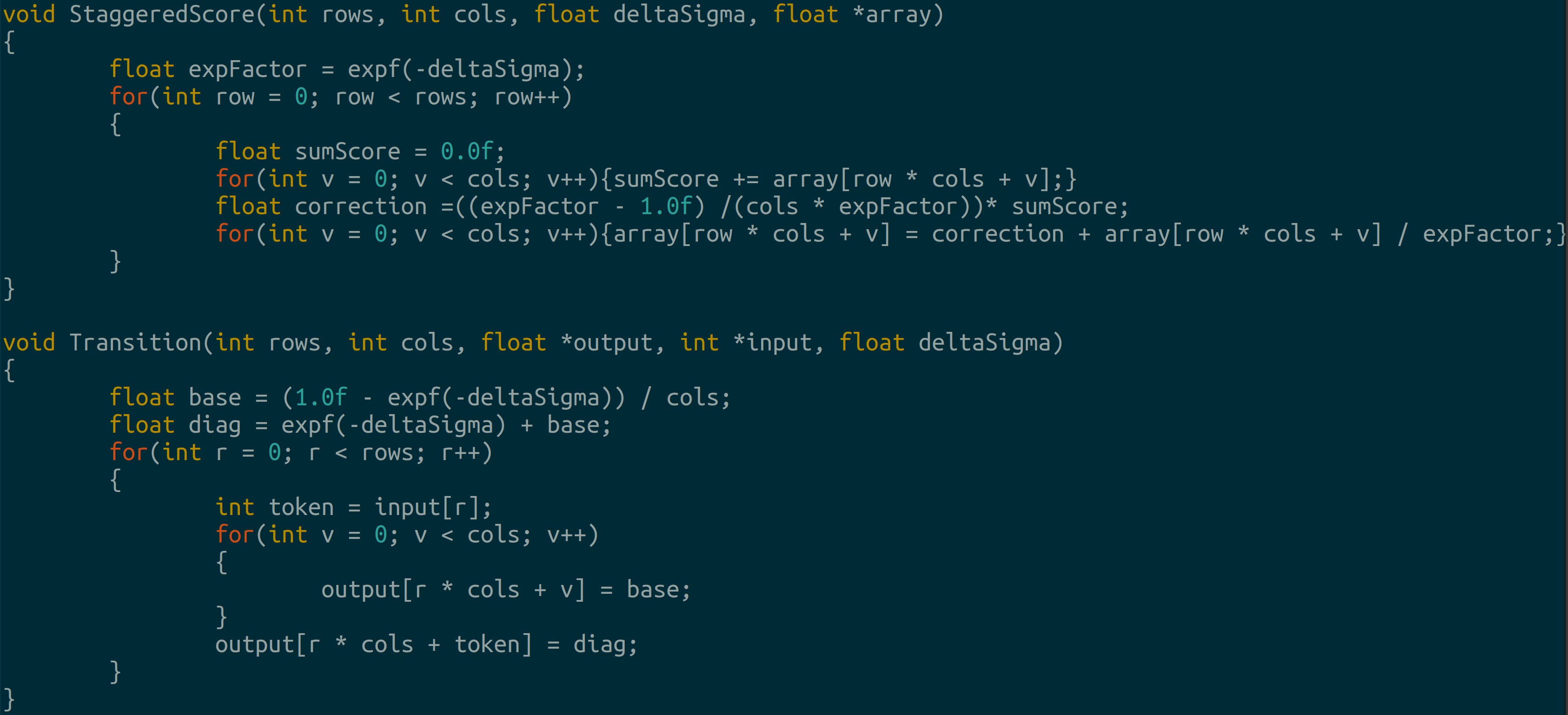
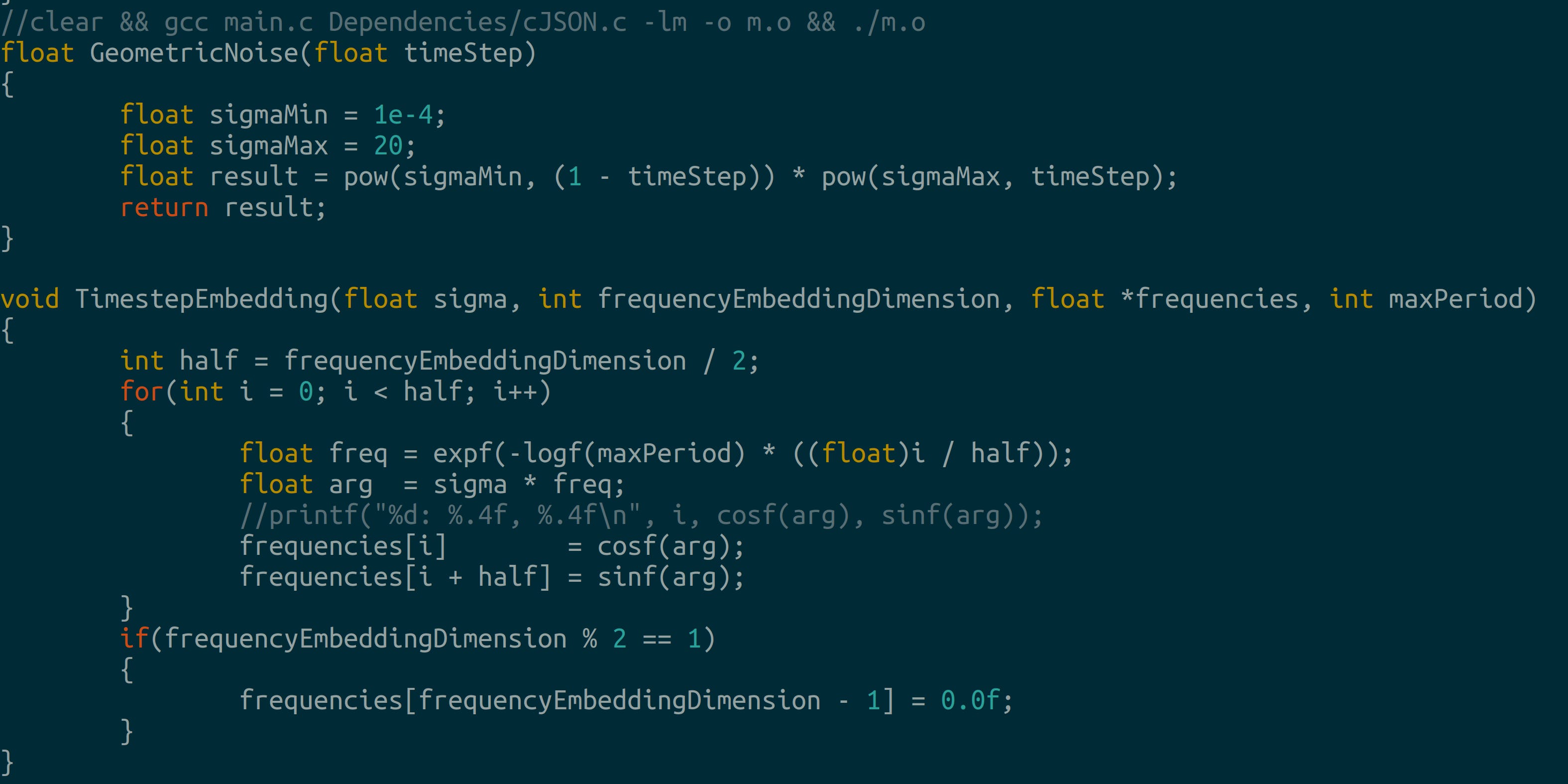
2.2 Tying Everything Together
We’re using the Shakespeare dataset and our trained model has context length of 256 tokens. We hardcode a random input as well:
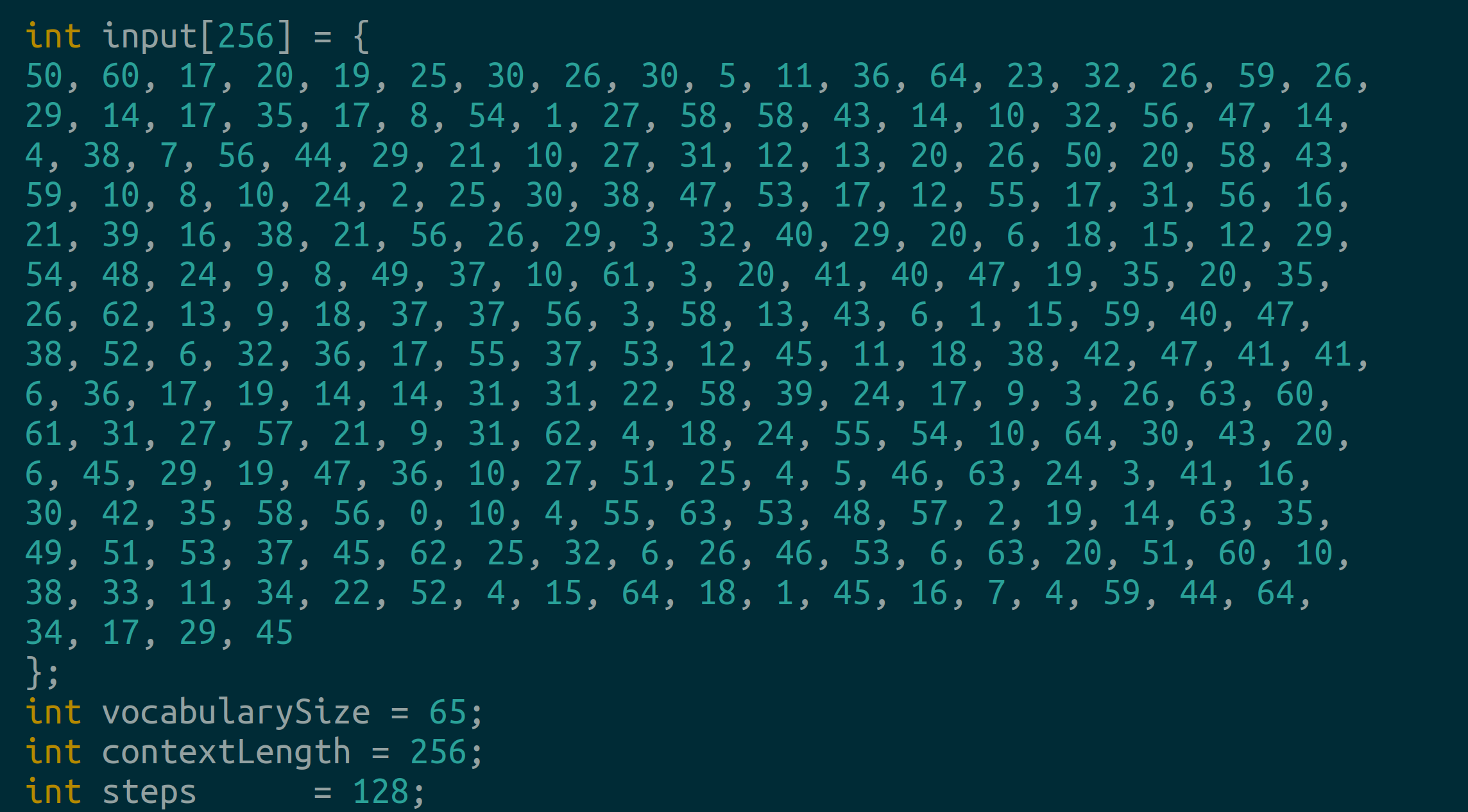
Next, we denoise across different timesteps. The idea is to generate noise sigmas, denoise in the forward pass, obtain probabilites and use these to update our inputs:
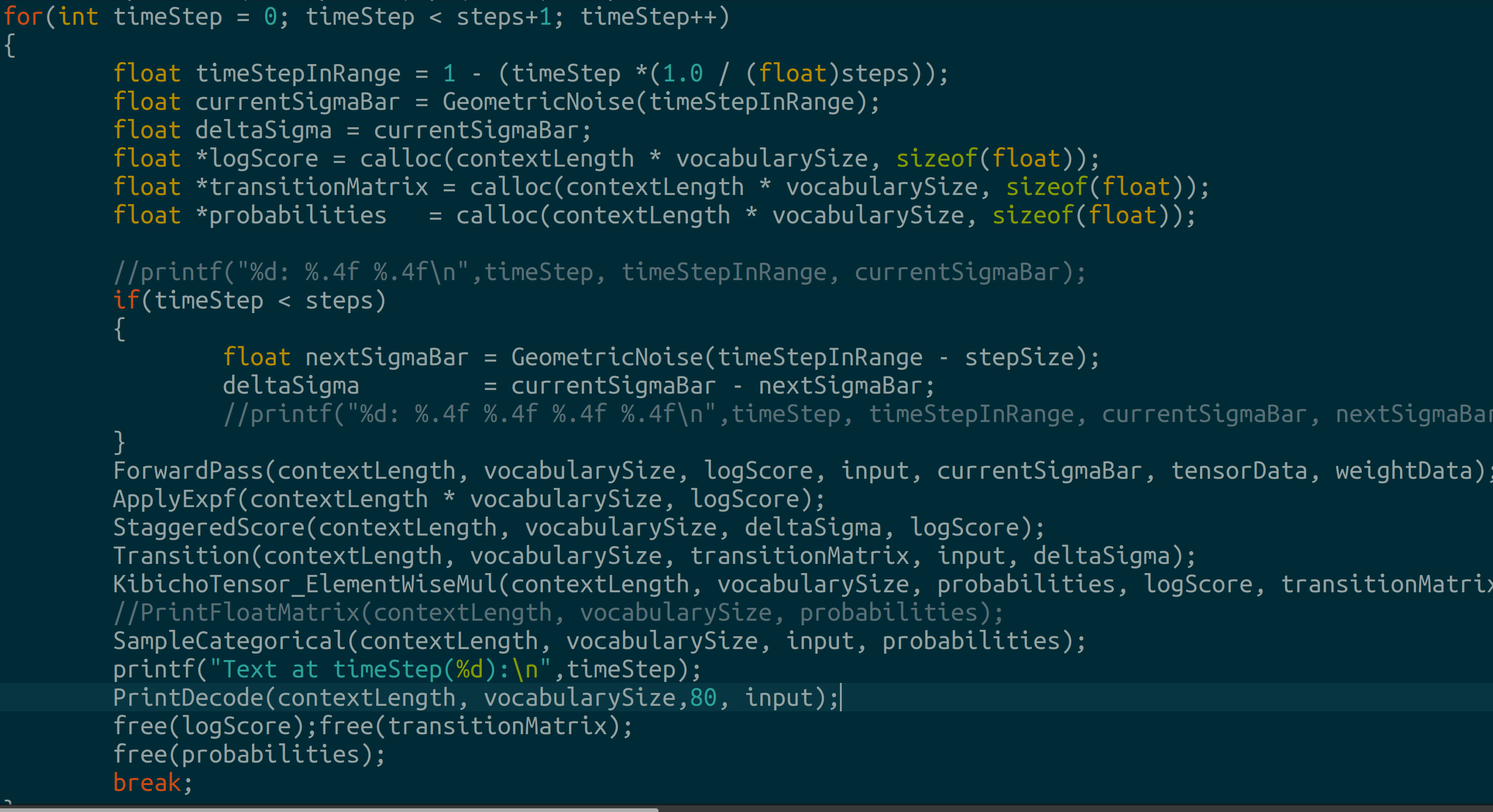
Now we code the forward pass using the model card provided at the section’s start. First we define some more hyperparameters:
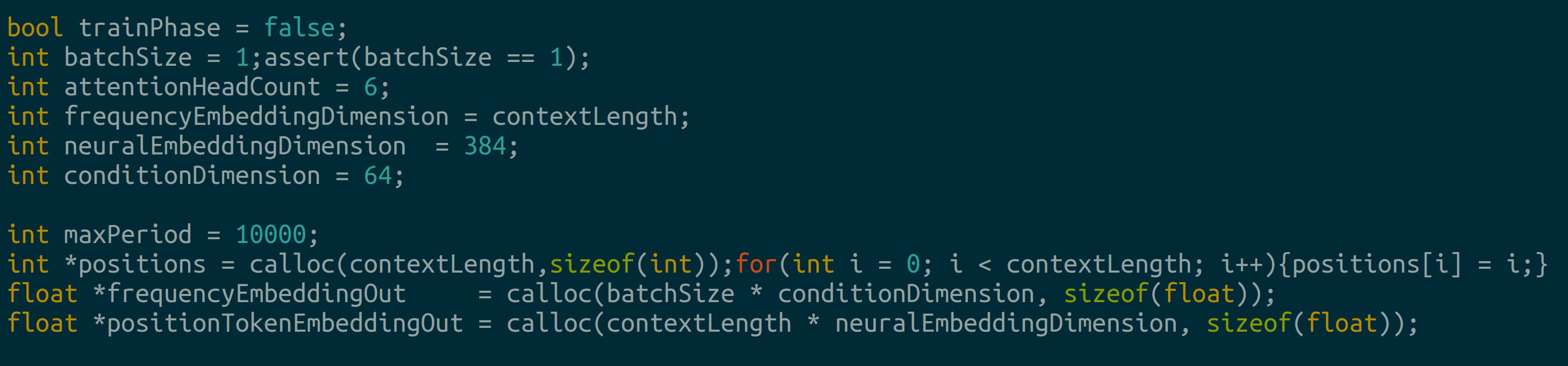
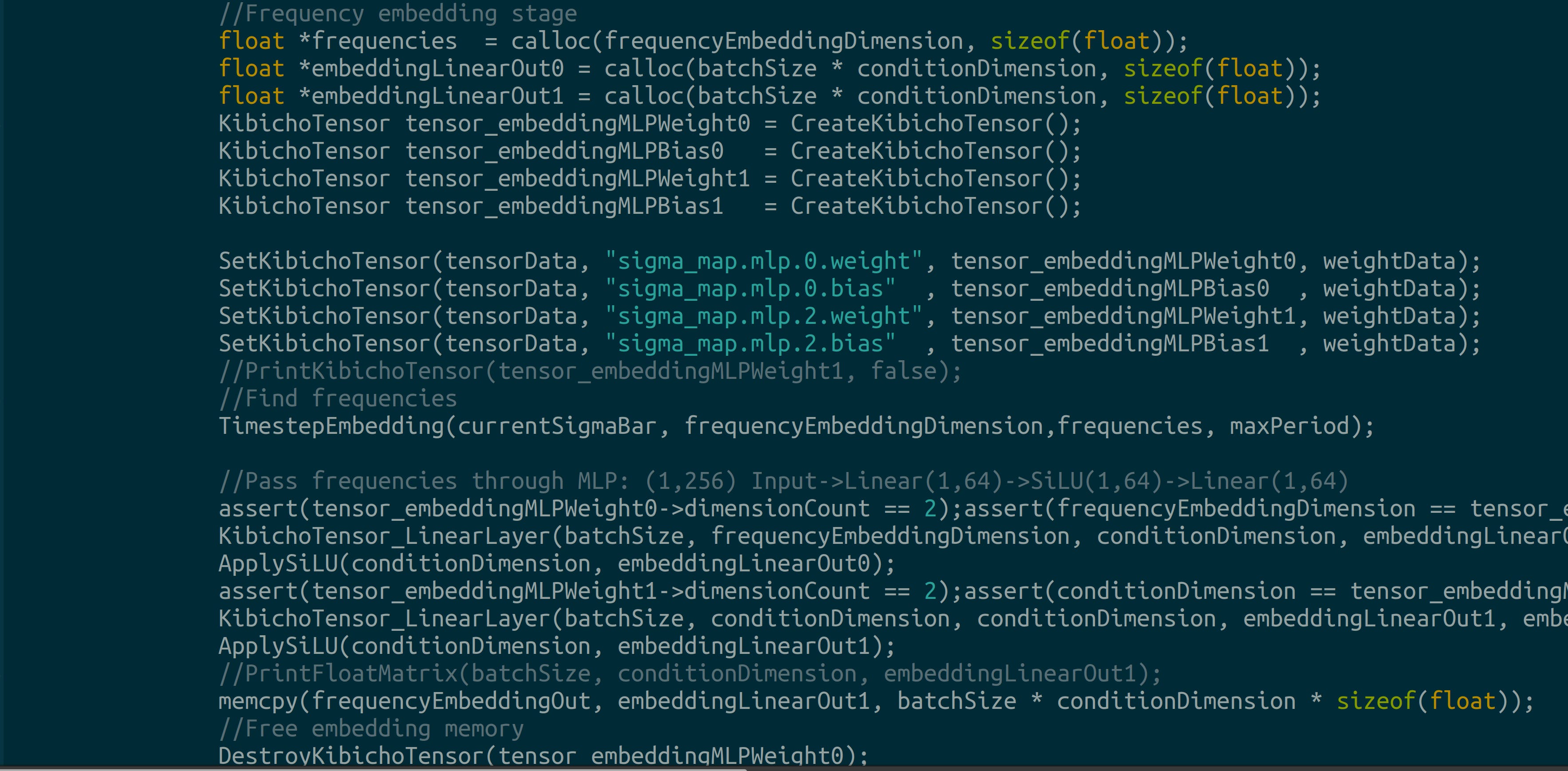
Next, we generate frequency embeddings for our input:
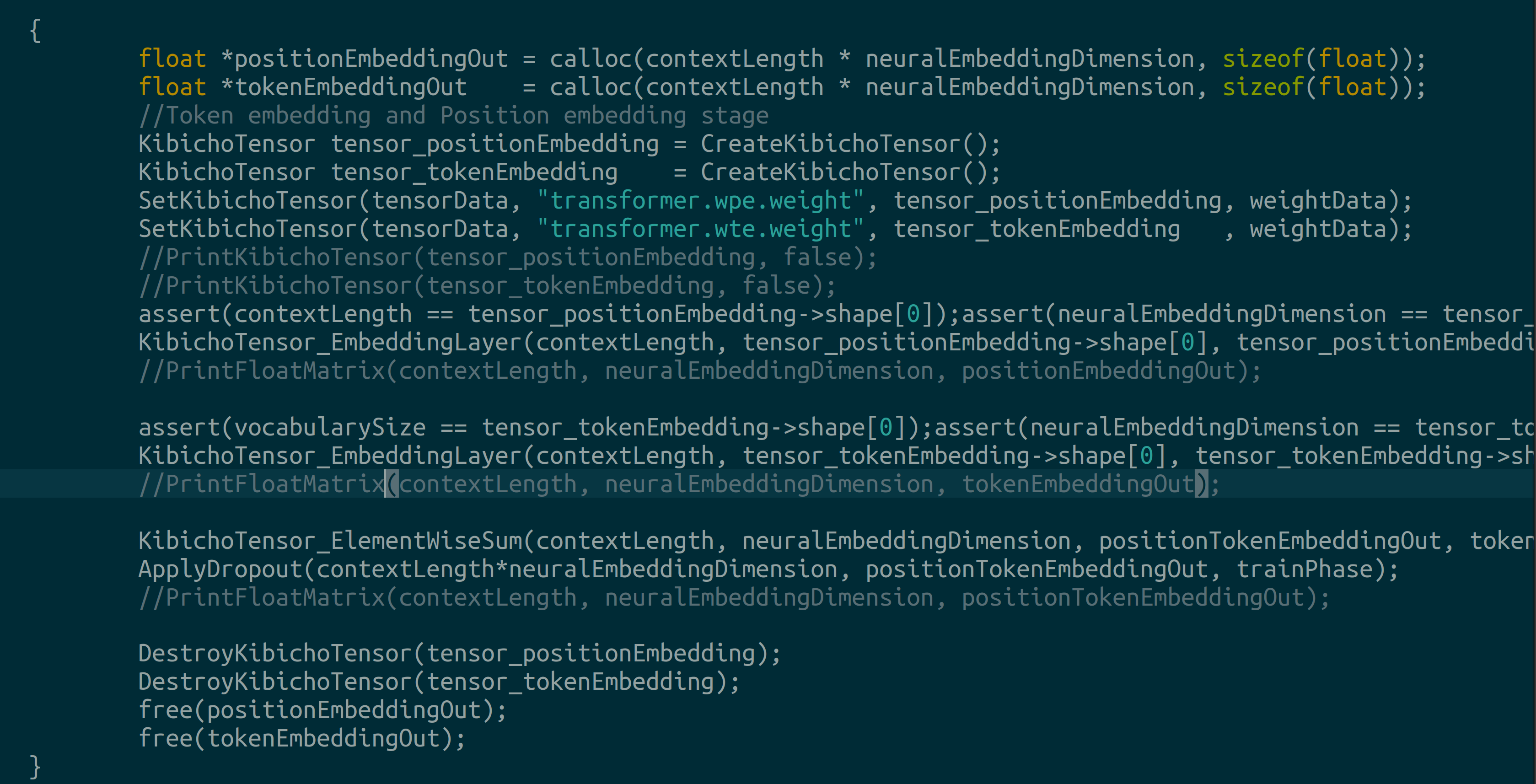
We proceed to generate position and token embeddings:
The diffusion block comes next and it’s the usual: layernorm, attention, layernorm, MLP combo. Nothing special:





Layernorm comes after the diffusion blocks:

Then the final layer is modulations, linear passed and a final layer norm:
Finally, we zero out our current input’s scores at the very end of our forward pass:

3.0 Running the model
In Python, the model runs pretty fast (takes a second to generate):
Our C version works great but is unoptimized. So it takes 30 minutes to run:
Sign up for part two where we optimize GEMM for fast matmuls with cache optimization and our previous Strassen’s algorithm implementation.
References
Lou, A., Meng, C., & Ermon, S,. (2024). Discrete Diffusion Modeling by Estimating the Ratios of the Data Distribution. Arxiv Link.
Letitia, P. (2024). Discrete Diffusion Modeling by Estimating the Ratios of the Data Distribution – Paper Explained. Substack Link.
Louaaron. (2024). Score Entropy Discrete Diffusion. GitHub Repo.
Ash80. (2025). The Annotated Discrete Diffusion Model. GitHub Repo.
Ho, J., Jain, A., & Abbeel, P. (2020). Denoising diffusion probabilistic models (arXiv preprint arXiv:2006.11239). arXiv. https://arxiv.org/abs/2006.11239
Song, J., Meng, C., & Ermon, S. (2021). Denoising diffusion implicit models. In International Conference on Learning Representations. OpenReview.
Permenter, F., & Yuan, C. (2024). Interpreting and improving diffusion models from an optimization perspective. Proceedings of the 41st International Conference on Machine Learning, Proceedings of Machine Learning Research, 235, 40461–40483. https://proceedings.mlr.press/v235/permenter24a.html
Song, Y., Sohl-Dickstein, J., Kingma, D. P., Kumar, A., Ermon, S., & Poole, B. (2021). Score-based generative modeling through stochastic differential equations. In International Conference on Learning Representations. OpenReview.
The Annotated Discrete Diffusion Models: Model Config. Google Colab Cell Link.





